In today’s digital landscape, searching for information is integral to our daily lives, whether for education, research, work, or shopping. However, as the volume and complexity of data kept growing, traditional search methods faced more and more challenges in providing accurate and relevant results. That’s where vector search comes in. We’re already seeing Google changing its search engine to empower the vector search (RankBrain, BERT, Neural matching), and expecting even greater incorporation of AI tools to improve search experience. Let’s explore the differences between traditional (keyword) search and vector search to understand how these technologies are shaping our search experiences, and how this impacts the discoverability of any content you might produce.
Traditional (keyword) search
Traditional search performs exact keyword matching from user queries to the data to retrieve relevant results. For example, searching for “programming languages” with traditional search will list every source containing those words. A more advanced version can also incorporate additional rules to enhance search results, such as:
keyword frequency (how often the term “programming languages” is used within the result text),
the presence of related terms (e.g. “Java”, “Python”, “C++” versus “cooking”, “gardening”),
or location (results closer to your location are favored).
While this approach has served us well, it struggles with ambiguous language, synonyms as well as the impact of SEO strategies, often resulting in less accurate or less valuable search results. This can be especially frustrating for businesses who are trying to get their content seen by the right people. For example, a business that publishes a blog post about “sustainable fashion tips” might miss out on potential customers who are searching for “eco-friendly clothing recommendations” or “green clothing ideas,” simply because their keywords don’t exactly match.
Vector (semantic) search
2D Vector Space Representation. In this space, “Python” and “Java” are close to each other as well as to the “Programming language” query we are searching for because they are similar (they share high values in their features).
On the other hand, vector search takes a different approach by seeking out related objects that share similar characteristics or semantics. You can think of it as finding results based on meaning or understanding rather than just exact wording. For example, searching for “programming languages” with vector search will not only find sources mentioning those exact words but also identify specific languages like “Python” or “Java” as well as related concepts such as “coding tutorials” or“development frameworks”.
To do a vector search, first of all, the content, such as texts, images, audio files, or videos, needs to be represented as vectors/embeddings (also often called vector embeddings) by AI models. These embeddings represent data in a multidimensional vector space. Vectors capture the essence or semantics of the data they represent while remaining computationally efficient.
Once these vector representations are generated, they are basically sets of numbers, and therefore easy to compute with. For instance, instead of searching for a specific word in text, we aim to find the closest vector (from the text embeddings) to the query vector (representing the word we’re searching for). This process relies on well-established vector computing methods, such as calculating the distance between vectors or minimizing the angle between them (Cosine similarity).
Comparison
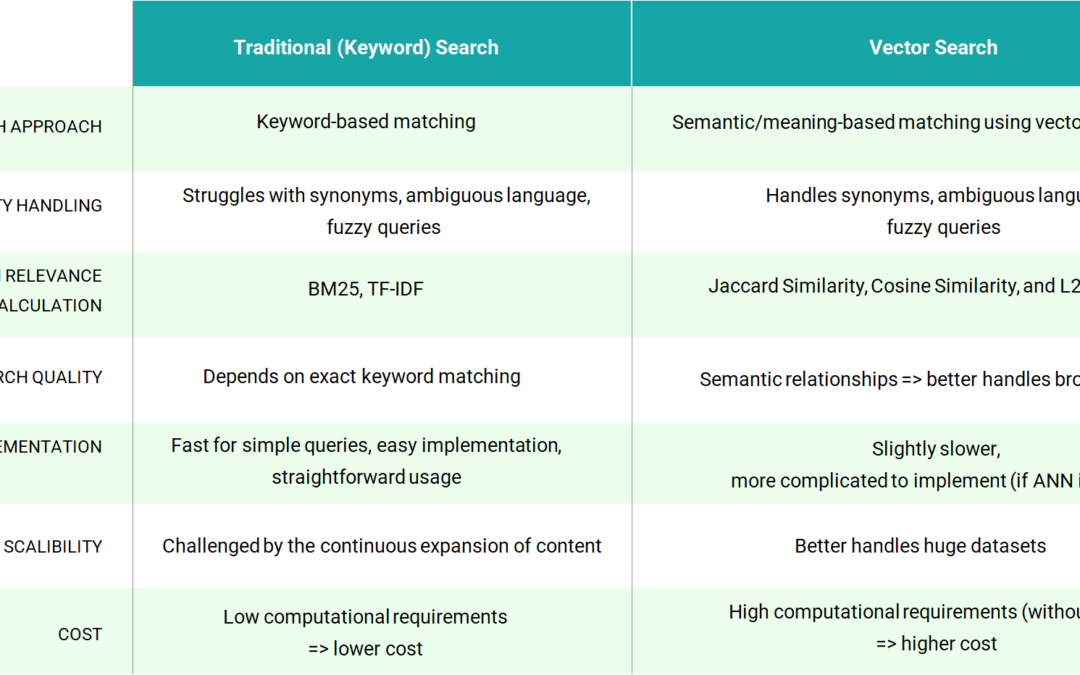
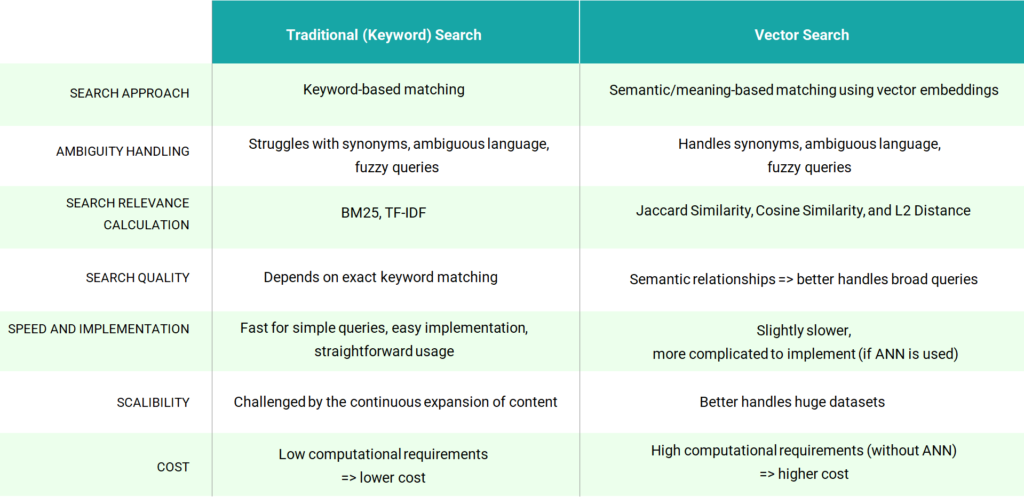
Let’s now compare different aspects of searching to understand the main differences between traditional search and vector search (also summarized in Table).
Search Approach In traditional search, the approach relies on matching keywords directly from the user query to the content. Vector search uses vector embeddings to catch the semantics of the data to perform a meaning-based approach.
Ambiguity handling Therefore, vector search shines when it comes to handling ambiguity. It is superior for handling synonyms, ambiguous language, and broad or fuzzy queries compared to traditional search. This also automatically influences the relevance of the search results.
Search relevance calculation The metrics used for search relevance calculations are different. The traditional search uses term frequency-inverse document frequency (TF-IDF) and BM25, while vector search uses Jaccard Similarity, Cosine Similarity, and L2 Distance (or Euclidean).
Speed and Implementation Traditional search is easy to implement, straightforward in usage, and fast for simple queries. Vector search may be slower for simple queries and more complicated to implement, once it comes to huge datasets. However, the implementation of approximate nearest neighbor techniques (ANN) allows to significantly speed up the process.
Scalability Continuous expansion of content, challenges the scalability of traditional search, while for vector search scalability is one of the advantages.
Cost While traditional search may have lower computational requirements, the superior performance and accuracy of vector search often justify the investment in additional computing power. Furthermore, the computational costs for vector search can be significantly reduced with the use of ANN.
Conclusions
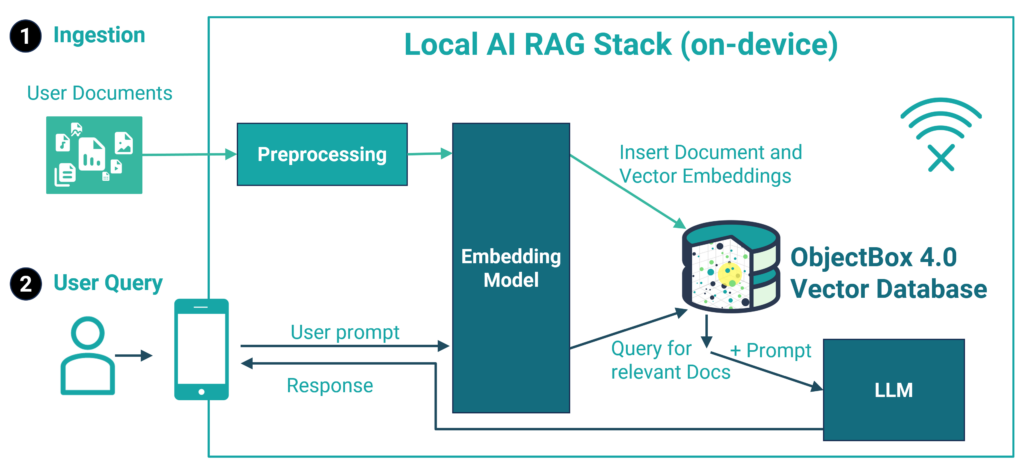
In summary, both traditional search and vector search offer distinct advantages and drawbacks. Vector search excels in handling ambiguity, correcting typos, enhancing relevance, and managing extensive datasets. Traditional search remains advantageous for straightforward queries, exact matches, or smaller datasets. Historically, limited computational resources, particularly for on-device computation (i.e. Edge Computing), favored traditional search. However, the landscape is evolving rapidly with the introduction of the first edge vector database solution by ObjectBox. This innovation promises to revolutionize the scenario by optimizing vector search for devices with constrained resources, extending the benefits of semantic search to the Edge.
ObjectBox 4.0 introduces the first on-device vector database for the Dart/Flutter platform, allowing Dart developers to enhance their apps with AI in ways previously not possible. A vector database facilitates advanced data processing and analysis, such as measuring semantic similarities across different document types like images, audio files, and texts. If you want to go all-in with on-device AI, combine the vector search with a large language model (LLM) and make the two interact with individual documents. You may have heard of this as “retrieval-augmented generation” (RAG). This is your chance to explore this as one of the first Dart developers.
Vector Search for Dart/Flutter
Now, let’s look into the Dart specifics! With this release, it is possible to create a scalable vector index on floating point vector properties. It’s a very special index that uses an algorithm called HNSW. It’s highly scalable and can find relevant data within millions of entries in a matter of milliseconds.
Let’s have a deeper look into the example used in our vector search documentation. In this example, we use cities with a location vector to perform proximity search. Here is the City entity and how to define a HNSW index on the location (it would also need additional properties like an ID and a name, of course):
1
2
3
4
5
6
@Entity()
classCity{
@HnswIndex(dimensions:2)
@Property(type:PropertyType.floatVector)
List<double>?location;
}
Vector objects are inserted as usual (the indexing is done automatically behind the scenes):
1
2
3
4
5
6
finalbox=store.box<City>();
box.putMany(
City("Barcelona",[41.385063,2.173404]),
City("Nairobi",[-1.292066,36.821945]),
City("Salzburg",[47.809490,13.055010]),
]);
To perform a nearest neighbor search, use the new nearestNeighborsF32(queryVector, maxResultCount) query condition and the new “find with scores” query methods (the score is the distance to the query vector). For example, to find the 2 closest cities:
In the cities example above, the vectors were straight forward: they represent latitude and longitude. Maybe you already have vector data as part of your data, but often, you don’t. So where do you get the vectors from?
For most AI applications, vectors are created by a so-called embedding model. There are plenty of embedding models to choose from, but first you have to decide if it should run in the cloud or locally. Online embeddings are the easier way to get started. Just set up an account at your favorite AI provider and create embeddings online. Alternatively, you can also run your embedding model locally on device. This might require some research. A good starting point for that may be TensorFlow lite, which also has a Flutter package. If you want to use really good embedding models (starting at around 90 MB), you can also check these on-device embedding models. These might require a more capable inference runtime though. E.g. if you are targeting desktops, you could use ollama (e.g. using this package).
CRUD benchmarks 2024
A new release is also a good occasion to refresh our open source benchmarks. Have a look:
CRUD is short for the basic operations a database does: Create, Read, Update and Delete. It’s an important metric for the general efficiency of a database.
Disclaimer 1: The benchmark uses synchronous methods if they are available. The rationale behind this was that we wanted to measure the plain database performance without any “async overhead” introduced by the Dart VM (eliminate an “external” factor). However, we are aware of this issue and will include asynchronous operations in a future version of the benchmarks.
Disclaimer 2: Our focus is the “Object” performance (you may find a hint for that in our product name 🙂); so e.g. relational systems may perform a bit better when you directly work with raw columns and rows.
Disclaimer 3: Hive’s read performance was cut off at 4 million/s. For reading, Hive is basically a hashtable that stores all objects in memory (e.g. everything must fit into memory). We measured 25 million/s.
Disclaimer 4: There cannot be enough disclaimers on any performance benchmark. It’s a complex topic where details matter. It’s best if you make your own picture for your own use case. We try to give a fair “arena” with our open source benchmarks, so it could be a starting point for you.
What’s next?
We are excited to see what you will build with the new vector search. Let us know! And please give us feedback. It’s the very first release of an on-device vector database ever – and the more feedback we get on it, the better the next version will be.
The new on-device vector database enables advanced AI applications on small restricted devices like mobile phones, Raspberry Pis, medical equipment, IoT gadgets and all the smart things around you. It is the missing piece to a fully local AI stack and the key technology to enable AI language models to interact with user specific data like text and images without an Internet connection and cloud services.
An AI Technology Enabler
Recent AI language models (LLMs) demonstrated impressive capabilities while being small enough to run on e.g. mobile phones. Recent examples include Gemma, Phi3 and OpenELM. The next logical step from here is to use these LLMs for advanced AI applications that go beyond a mere chat. A new generation of apps is currently evolving. These apps create “flows” with user specific data and multiple queries to the LLM to perform complex tasks. This is also known as RAG (retrieval augmented generation), which, in its simplest form, allows one to chat with your documents. And now, for the very first time, this will be possible to do locally on restricted devices using a fully fledged embedded database.
What is special about ObjectBox Vector Search?
We know restricted devices. Where others see limitations, we see the potential and we have repeatedly demonstrated creating superefficient software for these. And thus maximizing speed, minimizing resource use, saving battery life and CO2. With this knowledge, we approached vector search in a unique way.
Efficient memory management is the key. The challenge with vector data is that on the one hand, it consumes a lot of memory – while on the other hand, relevant vectors must be present in memory to compute distances between vectors efficiently. For this, we introduced a special multi-layered caching that gives the best performance for the full range of devices; from memory-constrained small devices to large machines that can keep millions of vectors in memory. This worked out so well that we saw ObjectBox outperform several vector databases built for servers (open source benchmarks coming soon). This is no small feat given that ObjectBox still holds up full ACID properties, e.g. caching must be transaction-aware.
Also, keep in mind that ObjectBox is a fully capable database that allows you to store complex data objects along with vectors. From an ObjectBox data model point of view, a vector is “just” another property type. This allows you to store all your data (vectors along with objects) in a single database. This “one database” approach also includes queries. You can already combine vector search with other conditions. Note that some limitations still apply with this initial release. Full hybrid search is close to being finished and will be part of one of the next releases.
In short, the following features make ObjectBox a unique vector database:
Embedded Database that runs inside your application without latency
Vector search based is state-of-the-art HNSW algorithm that scales very well with growing data volume
HNSW is tightly integrated within our internal database. Vector Search doesn’t just run “on top of database persistence”.
With this deep integration we do not need to keep all vectors in memory.
Multi-layered caching: if a vector is not in-memory, ObjectBox fetches it from disk.
Not just a vector database: you can store any data in ObjectBox, not just vectors. You won’t need a second database.
Low minimum hardware requirements: e.g. an old Raspberry Pi comfortably runs ObjectBox smoothly.
Low memory footprint: ObjectBox itself just takes a few MB of memory. The entire binary is only about 3 MB (compressed around 1 MB).
Scales with hardware: efficient resource usage is also an advantage when running on more capable devices like the latest phones, desktops and servers.
ObjectBox additionally offers commercial editions, e.g. a Server Cluster mode, GraphQL, and of course, ObjectBox Sync, our data synchronization solution.
Why is this relevant? AI anywhere & anyplace
With history repeating itself, we think AI is in a “mainframe era” today. Just like clunky computers from decades before, AI is restricted to big and very expensive machines running far away from the user. In the future, AI will become decentralized, shifting to the user and their local devices. To support this shift, we created the ObjectBox vector database. Our vision is a future where AI can assist everyone, anytime, and anywhere, with efficiency, privacy, and sustainability at its core.
What do we launch today?
Today, we are releasing ObjectBox 4.0 with Vector Search for a variety of languages:
*) We acknowledge Python’s popularity within the AI community and thus have invested significantly in our Python binding over the last months to make it part of this initial release. Since we still want to smooth out some rough edges with Python, we decided to label Python an alpha release. Expect Python to quickly catch up and match the comfort of our more established language bindings soon (e.g. automatic ID and model handling).
One more thing: ObjectBox Open Source Database (OSS)
We are also very happy to announce that we will fully open source the core of ObjectBox. As a company we follow the open core model. Since we still have some cleaning up to do, this will happen in one of the next releases, likely 4.1.
“Release week”
With today’s initial releases, we are far from done yet. Starting next Tuesday, you can expect additional announcements from us. Follow us to get the news as soon as it is released.
What’s next?
This is our very first version of a “vector database”. And while we are very happy with this release, there are still so many things to do! For example, we will optimize vector search by adding vector quantization and integrate it more tightly with our data synchronization. We are also focusing on expanding our solution’s reach through strategic partnerships. If you think you are a good fit, let us know. And as always, we are very eager to get some feedback from you! Take care.
SQLite and SQLite alternatives - databases for the Mobile and IoT edge
Overview of SQLite and SQLite alternatives as part of the mobile / edge database market with a comprehensive comparison matrix (last updated autumn 2024)
Therefore, there is a renewed need for on-device databases like SQLite and SQLite alternatives to persist and manage data on edge devices. On top, due to the distributed nature of the edge, there is a need to manage data flows to / from and between edge devices. This can be done withEdge Databases that provide a Data Sync functionality (SQLite alternatives only, as SQLite doesn’t support this). Below, we’ll take a close look at SQLite and its alternatives with consideration of today’s needs.
Databases for the Edge
While being quite an established market with many players, the database market is still growing consistently and significantly. The reason is that databases are at the core of almost any digital solution, and directly impact business value and therefore never going out of fashion. With the rapid evolvements in the tech industry, however, databases evolve too. This, in turn, yields new database types and categories. We have seen the rise of NoSQL databases in the last 20 years, and more recently some novel database technologies, like graph databases and time-series databases, and vector databases.
With AI and accordingly vector databases being all the hype since 2022/2023, the database market is indeed experiencing fresh attention. Due to the speed with which AI is evolving, we’re however already leaving the “mainframe era of AI” and entering the distributed Edge AI space. With SQLite not supporting vector search and related vector database functions, this adds a new dimension to this ever-present topic. There is a need for local, on-device vector databases to support on-device AI that’s independent of an Internet connection, reliably fast, and keeps data on the device (100% private).
Both, the shift back from a centralised towards a decentralised paradigm, and the growing number of restricted devices call for a “new type” of an established database paradigm. SQLite has been around for more than 20 years and for good reason, but the current market shift back to decentralized computing happens in a new environment with new requirements. Hence, the need for a “new” database type, based on a well-established database type: “Edge databases”. Accordingly, a need for SQLite alternatives that consider the need for decentralized data flows and AI functionalities (depending on the use case of course; after all SQLite is a great database).
What is an Edge Database?
Edge databases are a type of databases that are optimised for local data storage on restricted devices, like embedded devices, Mobile, and IoT. Because they run on-device, they need to be especially resource-efficient (e.g. with regards to battery use, CPU consumption, memory, and footprint). The term “edge database” is becoming more widely-used every year, especially in the IoT industry. In IoT, the difference between cloud-based databases and ones that run locally (and therefore support Edge Computing) is crucial.
What is a Mobile Database?
We look at mobile databases as a subset of edge databases that run on mobile devices. The difference between the two terms lies mainly in the supported operating systems / types of devices. Unless Android and iOS are supported, an edge database is not really suited for the mobile device / smartphone market. In this article, we will use the term “mobile database” only as “database that runs locally on a mobile (edge) device and stores data on the device”. Therefore, we also refer to it as an “on-device” database.
What are the advantages and disadvantages of working with SQLite?
SQLite is a relational database that is clearly the most established database suitable to run on edge devices. Moreover, it is probably the only “established” mobile database. It was designed in 2000 by Richard Hipp and has been embedded with iOS and Android since the beginning. Now let’s have a quick look at its main advantages and disadvantages:
Advantages
Disadvantages
20+ years old (should be stable ;))
Toolchain, e.g. DB browser
No dependencies, is included with Android and iOS
Developers can define exactly the data schema they want
Full control, e.g. handwritten SQL queries
SQL is a powerful and established query language, and SQLite supports most of it
Debuggable data: developers can grab the database file and analyse it
20+ years old ( less state-of-the-art tech)
Using SQLite means a lot of boilerplate code and thus inefficiencies ( maintaining long running apps can be quite painful)
No compile time checks (e.g. SQL queries)
SQL is another language to master, and can impact your app’s efficiency / performance significantly…
The performance of SQLite is unreliable
SQL queries can get long and complicated
Testability (how to mock a database?)
Especially when database views are involved, maintainability may suffer with SQLite
What are the SQLite alternatives?
There are a bunch of options for making your life easier, if you want to use SQLite. You can use an object abstraction on top of it, an object-Relational-Mapper (ORM), for instance greenDAO, to avoid writing lots of SQL. However, you will typically still need to learn SQL and SQLite at some point. So what you really want is a full blown database alternative, like any of these: Couchbase Lite, Interbase, LevelDB, ObjectBox, Oracle Berkeley DB, Mongo Realm, SnappyDB, SQL Anywhere, or UnQLite.
While SQLite really is designed for small devices, people do run it on the server / cloud too. Actually, any database that runs efficiently locally, will be highly efficient on big servers too, making them a sustainable lightweight choice for some scenarios. However, for server / cloud databases, there are a lot of alternatives you can use as a replacement like e.g. MySQL, MongoDB, or Cloud Firestore.
Bear in mind that, if you are looking to host your database in the cloud with apps running on small distributed devices (e.g. mobile apps, IoT apps, any apps on embedded devices etc.), there are some difficulties. Firstly, this will result in higher latency, i.e. slow response-rates. Secondly, the offline capabilities will be highly limited or absent. As a result, you might have to deal with increased networking costs, which is not only reflected in dollars, but also CO2 emissions. On top, it means all the data from all the different app users is stored in one central place. This means that any kind of data breach will affect all your and your users’ data. Most importantly, you will likely be giving your cloud / database provider rights to that data. (Consider reading the general terms diligently). If you care about privacy and data ownership, you might therefore want to consider a local database option, as in an Edge Database. This way you can decide, possibly limit, what data you sync to a central instance (like the cloud or an on-premise server).
SQLite alternatives Comparison Matrix
To give you an overview, we have compiled a comparison table including SQLite and SQLite alternatives. In this matrix we look at databases that we believe are apt to run on edge devices. Our rule of thumb is the databases’ ability to run on Raspberry Pi type size devices. If you’re reading this on mobile, click here to view the full matrix.
Edge
Database
Short description
License / business model
Android / iOS*
Type of data stored
Central Data Sync
P2P Data Sync
Offline Sync (Edge)
Data level encryption
Flutter / Dart support
Vector Database (AI support)
Minimum Footprint size
Company
SQLite
C programming library;
probably still 90% market share in the small devices space (personal
assumption)
Embedded / portable database
with P2P and central synchronization (sync) support; pricing upon
request; some restrictions apply for the free version. Secure SSL.
Partly proprietary, partly
open-source, Couchbase Lite is BSL 1.1
Is there anything we’ve missed? What do you agree and disagree with? Please share your thoughts with us via Twitter or email us on contact[at]objectbox.io.
ObjectBox was a purely disk-based database until now. Today, we added in-memory storage as a non-persistent alternative. This enables additional use cases requiring temporary in-process data. It’s also great for testing.
Disk + In-memory: simply use the best of both worlds
When opening a new database, you can now choose if the database is stored on disk or in-memory. Because this is a per database option, it is possible to use both types in your application. It’s very simple to use: when opening the store, instead of providing an actual directory, provide an pseudo-directory as a string with the prefix “memory:”. After the prefix, you pick a name for the database to address it, e.g. “memory:myApp”.
Note: in-memory databases are kept after closing a store; they have to be explicitly deleted or are automatically deleted if the creating process exists.
So, what are typical in-memory database use cases?
Caching and temporary data
If data is short lived, it may not make sense involving the disk with persistent storage. Unlike programming language containers like maps and hash tables, caches built on in-memory databases have advanced querying capabilities and support complex object graphs. For example, databases allow lookups by more than one key (e.g. ID, name and URL). Or deleting certain entries using a query. As ObjectBox is closely integrated with programming languages, putting and getting an object are typically just “one liners” similar to map and hash table containers.
Bringing “online-only” and “offline-first” apps closer together
Let’s say you want to start simple by creating an application that always fetches the data from the cloud. You can put that data in an in-memory database (similar to the caching approach above). The data is available (“cached”) for all app components via a common Box-based API, which is already great. But let’s say later on, you want to go “offline-first” with your app to respond quicker to user requests and save cloud and/or mobile networking operator (MNO) costs. Since you are already using the Box-based API, you simply “turn on persistence” by using a disk-based database instead.
Performance and app speed
Shouldn’t this be the first point in the list? Well, ObjectBox did already operate at “in-memory speed” for mostly-read scenarios even though it used a disk-based approach. So, do not expect huge improvements for reads. Writes (Create, Update, Delete) are different though: to fully support ACID, a disk-based database must wait on the disk to fully complete the operation. Contrary to this, an in-memory database can immediately start the next transaction.
Diskless devices
Some small devices, e.g. sensors, may not have a disk or an accessible file system. This update makes it possible to run ObjectBox here too. This can be an interesting combination with ObjectBox Sync and automatically getting data from another device.
Testing
For example in unit tests, you can now spin up ObjectBox databases even faster than before, e.g. opening and closing a store in less than a millisecond.
“Transactional memory”
In concurrent (multi-threaded) scenarios, you may want to provide transactional consistent views (or “checkpoints”) of your data. Let’s say bringing the data from one consistent view to another is a rather complex operation involving the modification of several objects. In such cases locking may be a concern (complex or blocking), so having an in-memory database may be a nice alternative. It “naturally” offers transactions and thus transactional safe view on data. Thus, you can always read consistent data without worrying about data being modified at the same time. Also, you never have to wait for a modifying thread to finish.
What’s next?
This is only our first version of our in-memory store. Consider it as an starting point for more to come:
Performance: to ship early, we made rather big performance tradeoffs. At this point, starting a new write transaction will copy all data internally, which of course is not great for performance. A future version will be a lot smarter than that.
Persistence: While this version is purely in-memory without persistence, we want to add persistence gradually. This will include a write-ahead-log (WAL) and snapshots. This constellation may become even preferable over the default disk-base store for some scenarios.
We are currently rolling out the in-memory feature to all language supported by ObjectBox:
ObjectBox Admin (Docker container) allows you to analyze ObjectBox databases that run on desktop and server machines. Releasing ObjectBox Admin as a standalone Docker image makes it possible to run Admin on a larger number of platforms.
ObjectBox Admin is available as a Linux x86_64 Docker image, which runs on all common platforms including Windows and macOS. We offer a convenience script (objectbox-admin.sh) but it’s also simple enough to run it via plain Docker. See the docs for details, or get started by following this short tutorial.
Data Browser
The ObjectBox Admin Web App comprises a menu on the left (Data, Schema, Status, GraphQL…) and the corresponding content pane on the right-hand side.
The data browser provides a table of objects of a specific type. By clicking on the Type we can select an entity type for viewing its entity objects.
Next to the type selection is a small filter icon (the dashed triangle right of the type selection).
When selected, a query editor pops up that allows to filter data by adding a Property/Operator/Value expression.
When finished, click the check mark, and the data table gets updated with an active filter.
At the bottom, you will find a download link that exports the objects of the currently viewed box in JSON format.
Schema Browser
You can get a detailed list of elements that make up an object type in the “Schema” pane.
In accordance with the “Data” pane, you can click on Type to select the schema of a specific entity type of your database.
Status
Base level database and ObjectBox Admin information can be viewed on the “Status” pane.
GraphQL
The Docker-version of ObjectBox Admin offers a pane to query the database using GraphQL.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.Ok