Is it the year on on-device vector databases yet? Or at least on-device AI?
A year ago the interest in “on-device vector database” (also “local vector DB”, or “edge vector DB”) was mostly theoretical / experimental. While we saw SLMs appearing and rapdily dropping in size while gaining in capability, the market overall was not ready, even though vector database technology was already powering Apple Intelligence and shipped to very iPhone.
The only thing “missing” is the on-device memory layer: Vector databases engineered for phones, ECUs, and other restricted edge devices. Ok, it’s not entirely missing, but the on-device vector database is a genuinely small field of products engineered for phones and ECUs. And we’re going to take a deeper look into that market in this article.
Note: A lot of brands still claiming “on-device” are, in practice, running on a high-end developer laptop that is off Wi-Fi. This article is focused primarily on local AI on more restricted devices like e.g. smartphones, ECUs, and PoS systems.
Why now?
Well, a lot of things happened in parallel, finally allowing for on-device AI on a larger scale:
SLMs like Gemma 3n, Phi-3, Qwen 2.5 now run usefully under ~4 GB. Retrieval can therefore be paired with on-device generation without destroying the device’s memory budget.
Vectors got smaller: A 1,536-dimensional float32 vector is 6 KB. Quantized to 1 bit per dimension it is 192 bytes – a ~32× memory reduction with typical recall loss in the ~5–10% range depending on the model and reranking strategy.
The cloud cost conundrum[1] became real: Gartner and IDC, both, report rapidly growing cost numbers for cloud and AI infastructure and expect further climbs. IDC FutureScape 2026 warns that Global 1000 organisations will under-estimate their AI infrastructure costs by ~30% through 2027.
Privacy regulations came into effect: The EU AI Act Article 5 prohibitions came into force in early February 2025, general-purpose AI obligations from August 2025, and full enforcement is scheduled for 2 August 2026.
What “on-device” actually means
A “real” on-device / edge (or mobile) vector DB for Edge AI persists locally, supports vector + metadata/hybrid search, exposes mobile-usable SDKs (Java / Swift / Kotlin / Flutter) for Mobile and C / C++ for other embedded devices, handles incremental CRUD, has predictable and efficient RAM/storage, a small footprint, works offline, and ideally supports selective data sync. ANN indexing math is the easy part – the hard part is mobile lifecycle, thermal throttling, encrypted storage, and sync of derived data when source content changes. E.g. Faiss is a solid library and good for some use cases, but it is not a database. Let’s look at what’s out there and which criteria they currently meet.
What is an Edge Database?
Edge databases are a type of databases that are optimised for local data storage on restricted devices, like embedded devices, Mobile, and IoT. Because they run on-device, they need to be especially resource-efficient (e.g. with regards to battery use, CPU consumption, memory, and footprint). The term “edge database” is becoming more widely-used every year, especially in the IoT industry. In IoT, the difference between cloud-based databases and ones that run locally (and therefore support Edge Computing) is crucial.
What is a Mobile Database?
We look at mobile databases as a subset of edge databases that run on mobile devices. The difference between the two terms lies mainly in the supported operating systems / types of devices. Unless Android and iOS are supported, an edge database is not really suited for the mobile device / smartphone market. In this article, we will use the term “mobile database” only as “database that runs locally on a mobile (edge) device and stores data on the device”. Therefore, we also refer to it as an “on-device” database.
Vendor Map
We only cover options that can plausibly run on resource-constrained devices here. You can find more on general vector databases here, though that review is from 2024 and due to AI / the development of search we did not found it worthwhile updating. The on-device vector database is worth covering as it is only shaping and lacking broad coverage. Approximate footprint shown — always verify on your target hardware.
Segment
Vector Database
Approx. footprint
Sync
ACID
Metadata filter
Benchmarks / Efficiency
Status
Dedicated mobile / embedded DBs with vectors (vector search)
Note: Excluded due to size / minimum requirements or availability: Qdrant Edge announced July 2025 as a re-architected in-process variant (private beta, partner-curated); not publicly available; the publicly distributed Qdrant is a server (~900MB compiled binary). Milvus Lite — Python binary, Linux/macOS only; broader Milvus typically provisioned with multiple GB RAM. DuckDB VSS — analytics-class; ≥125MB RAM/thread minimum, 1–4GB/thread for optimal performance. SQL Server 2025 — server-class: ≥1GB RAM (Express) / ≥4GB (other editions), ≥6GB disk, x64 only.
Why “edge vector database” tech is different from cloud
Most of the columns above probably look familiar from any other database review. The reason this category is genuinely different from typical databases, and cloud / server vector databases in particular, comes down to four things:
Strict resource limits. In the cloud, performance problems can often be solved by scaling horizontally, adding memory, or moving to a larger instance. On a physical device, the compute, RAM, flash etc. are fixed. That changes the underlying architecture and the dilligence required in development: indexing, query execution, persistence, and sync all need to be efficient by design rather, because you cannot compensate with “throwing resources at the problem”.
Energy budgets matter. On battery-powered devices, every query, write, compaction, sync, and re-embedding job also competes with the user experience, thermal limits, and battery life – constraints a cloud database usually does not face directly (more costs though…).
The edge is fragmented. “Edge” can mean a smartphone, an ECU, a PoS terminal, a Linux gateway, an industrial PC, or a microcontroller-class device. These systems vary widely in operating system, CPU architecture, storage, available RAM, update model, security requirements, and connectivity. A credible edge vector database therefore needs more than ANN search; it needs predictable behavior across constrained and heterogeneous environments.
Sync is hard. I would say harder than search. Vectors are derived data. When source content changes, permissions change, or the embedding model is upgraded, old embeddings may become stale. An edge vector database therefore needs to handle not only local search, but also updates, deletes, re-indexing, and selective sync between device and cloud. This is where a database matters more than a standalone ANN library.
Do you actually need an on-device vector database? When?
As always: It depends. Use on-device vector DBs when (basically when you need Edge Computing):
you have privacy requirements; data is personal; you face compliance needs
the app needs to work when offline, or reliably under flaky network conditions
you want speed (think UX) or you need quaranteed response times (QoS)
you need to cut networking and cloud costs to make the economics work
Let’s look at some cases where on-device vector databases are truly needed.
Mobile Apps
The strongest mobile use case currently isn’t generic “AI on phones,” but private assistant memory and context for RAG-based apps: AI chats or assistants that can answer questions using personal, app-specific, or domain-specific knowledge, for example in travel, product support, field service, or maintenance.
Notes, messages, files, photos, app activity, preferences, and location-specific history are already on the device. An on-device vector database lets an assistant embed that context locally into an on-device vector DB, retrieve it instantly, and sync only selected data when needed. That makes the experience faster and more private, while keeping the app useful even when connectivity is poor.
Domain-specific knowledge is often not publicly available to a general-purpose AI model. It may only exist inside an app, a downloaded manual, a product catalog, or a company’s technical documentation. In those cases, the app can use this semantic context through a local vector database. For example, a maintenance assistant could store heating-system technical docs on the phone, identify a part or problem from a photo, retrieve the relevant repair instructions, and suggest targeted fixing steps. Added benefit: it still works in the cellar.
Vehicles / ECUs
Vehicles are a strong fit because software-defined vehicles need cloud-scale learning, but in-car execution cannot depend on perfect connectivity. McKinsey says automotive software and electronics are moving toward zonal and central compute architectures for OTA updates, connectivity, and gen AI, with the market reaching $519 billion by 2035. The vector DB role is a compact local memory layer for in-cabin assistants, offline manual search, driver personalization, predictive diagnostics, and retrieval over vehicle logs or VSS-normalized signals. McKinsey’s edge-AI survey reinforces the hybrid stance: stakeholders cited offline availability (39%), latency (35%), privacy/security (20%), and network data cost (6%) as main factors for moving AI onboard; they also flagged SoC constraints (46%) and energy consumption (35%) as limits on what can run in the vehicle. So the answer is not cloud vs. edge; it is local-first retrieval and selective sync to the backend. This is the same position as the ObjectBox / MongoDB architecture: ObjectBox handles low-latency local operations and bi-directional sync connects selected data to MongoDB Atlas for storage, analytics, retraining, and coordination.
Point-of-sales systems
PoS systems often work on premises with flaky network conditions and offline and hybrid payment models improve payment resilience, accepting cash and card payments offline and uploading them after reconnection. A local vector layer makes sense when the PoS wants to improve the service and customer experience with AI features, e.g. with semantic lookup over products, promotions, policies, allergens, prior orders etc. 67% of retail executives expect AI-driven personalization capabilities in 2026, and McKinsey’s 2026 retail research says AI is reshaping discovery and purchase behavior as stores remain important. The pattern is local operations first, cloud analytics later: answer routine queries instantly in-store, then sync selected sales, stock, customer, and personalization data when the network is available.
Bottom line
The bottom line: on-device vector databases are moving from “interesting idea” to a much needed enabler for local AI. Not every app needs one, and many workloads will stay cloud-first, but y hybrid AI approach combining the best of the edge and the cloud is often benefitial. Whenever data is private, latency-sensitive, cost-sensitive, or needed offline, pushing vector search to the device makes a lot of sense. On top, finding the right balance between on-device AI and cloud AI helps save costs, and energy, and is therefore economically and environmentally the most sustainable option. The hard part is not just an ANN search, which a small dedicated lib can easily do; it is efficient persistence, updates, deletes, metadata filtering, sync, footprint, and predictable behavior under real device constraints. If we predict the future from the past, shrinking large server / cloud vector databases to work on edge devices will not work. Instead, this market needs dedicated and highly optimized solutions. Therefore, we believe, it will be won by databases actually engineered for the edge.
ObjectBox 5.0 delivers the most requested updates across the board. If you are building an offline-first application and need a seamless Data Sync solution, we believe, this is the upgrade you have been waiting for:
New Sync Filters for true user-specific data sync (GA)
A new MongoDB Sync Connector (GA)
5.0 database/client releases for Dart, Java/Kotlin, Swift, C, and C++
Better examples, stability improvements, and quality-of-life fixes
Smarter Sync: user-specific and with MongoDB
The big news is all around ObjectBox Sync and the two major new features: user-specific sync filters and connecting to MongoDB. After working closely with select customers for the last months, we are happy to announce the general availability for both features.
With 5.0, you can now define Sync Filters to control exactly which data each Sync user receives.
Define filter expressions on the server that run per user
Use auth/JWT and client-provided variables inside those filters
Enable “each user only sees their own data” without duplicating data or maintaining separate partitions
For the new MongoDB Sync Connector, we’ve partnered with MongoDB to create a tight integration:
Sync your data from and to MongoDB in “real time”
Edge setup for multiple locations: deploy one ObjectBox Sync Server per location, all syncing to one central MongoDB
Integrate ObjectBox-powered apps with an existing MongoDB database or analytics pipeline
This brings the best of both worlds: a fast, embedded offline-first database for your mobile, IoT, or embedded apps, and a central MongoDB store for backend integration, reporting, and other services. Best of all, you don’t need a custom application backend – the ObjectBox Sync Server handles the heavy lifting, keeping your app data in sync with MongoDB automatically.For more information, check our MongoDB page or the MongoDB Sync Connector documentation.
Migrating from Realm Device Sync?
If you are looking for an alternative to the deprecated MongoDB Realm Device Sync, ObjectBox is the natural choice. Like Realm, ObjectBox is object-oriented, making migrating from Realm to ObjectBox straightforward and fast. You get the same offline-first capabilities and out-of-the-box Data Sync you know plus: industry-leading speed and efficiency.
The ObjectBox database is known for its extremely high CRUD performance and vector search for AI use cases. It can be used as a standalone embedded database or in combination with ObjectBox Sync. As it is closely integrated into programming languages to offer native object persistence, the 5.0 release spans multiple releases:
All 5.0 Sync clients are compatible with the new Sync Filters and MongoDB Sync Connector. Check the release links above for language-specific improvements.
Further reading and links
There has never been a better time to build with ObjectBox. Here is how to get started:
Sync examples: includes a tasks application with clients for all platforms and a preconfigured Sync Server. Also includes a Docker Compose that boots up a MongoDB to sync with; it’s set up in a minute, give it a try!
Edge AI refers to decentralized artificial intelligence systems that process data locally on in-store devices, e.g. POS terminals, smart shelves, Raspberry Pis, mobile phones, or cameras, rather than relying on distant cloud servers. This architecture works independently from distant cloud servers or internet connectivity, and therefore offline with minimized latency. Both, offline-capability and speed, are critical for applications like fraud detection and checkout automation. Accordingly, IDC emphasizes that 45% of retailers now prioritize “near-the-network” edge deployments. There, AI models run locally on in-store servers or IoT devices, balancing cost and performance.
Key Components of Edge AI Systems
For Edge AI to deliver real-time, offline-capable intelligence, its architecture must integrate on-device databases, local processing, and efficient data synchronization. These three pillars ensure seamless AI-powered retail operations without dependence on the cloud, minimizing latency, costs, and privacy concerns.
Edge AI system architecture in retail, integrating local processing, real-time data sync, and various applications like POS or signage
Retail generates vast real-time data from IoT sensors, POS transactions, smart cameras, and RFID tags. To ensure instant processing and uninterrupted availability you need:
On-device data storage: All kinds of devices from IoT sensors to cameras capture data. Depending on the device capabilities, with small on-device databases, data can be stored and used directly on the devices.
Local central server: A centralized on-premise device (e.g. a PC or Raspberry Pi, or more capable hw) ensures operations continue even if individual devices are resource-limited or offline.
Bi-directional on-premise data sync: Local syncing between devices and with a central on-site server ensures better decisions and fail-safe operations. It keeps all devices up-to-date without internet dependence.
2. Local Data Processing & Real-Time AI Decision-Making
Processing data where it is generated is critical for speed, privacy, and resilience:
On-device AI models: Small, quantized AI models (SLMs) like Microsoft’s Phi-3-mini (3.8B parameters, <2GB memory footprint) can run directly on many devices (e.g. tablets, and POS systems), enabling real-time fraud detection, checkout automation, and personalized recommendations.
Local on-premise AI models: Larger SLMs or LLMs run on the more capable in-store hardware for security, demand forecasting, or store optimization.
On-device & on-premise vector databases: AI models leverage on-device vector databases to structure and index data for real-time AI-driven insights (e.g., fraud detection, smart inventory management), fast similarity searches, and real-time decision-making.
Selective Cloud Sync: Bi-directional cloud data sync extends the on-premise data sync. Select data, such as aggregated insights (e.g., sales trends, shrinkage patterns), payment processing, and select learnings are synced with the cloud to enable Enterprise-wide analytics & compliance, Remote monitoring & additional backup, and Optimized centralized decision-making.
Cloud Database & Backend Infrastructure: A cloud-based database acts as the global repository. It integrates data from multiple locations to store aggregated insights & long-term trends for AI model refinement and enterprise reporting, facilitating cross-location comparisons.
Centralized cloud AI model: A centralized cloud AI model is optional for larger setups. It can be used to continuously learn from local insights, refining AI recommendations and operational efficiencies across all connected stores.
Use Cases of Edge AI for Retailers
Edge AI is unlocking new efficiencies for retailers by enabling real-time, offline-capable intelligence across customer engagement, marketing, in-store operations, and supply chains.
Key applications of Edge AI in retail, driving personalization, operational efficiency, and smarter decision-making.
Enhancing Customer Experiences in Retail Stores with Edge AI – Examples
Edge AI transforms the shopping experience, enabling retailers to offer more streamlined and more personalized services based on real-time data, thereby boosting customer satisfaction and sales. Key benefits include:
Contactless Checkout: AI-driven self-checkouts allow customers to select products captured by cameras. Thus, bypassing the need for scanning product codes, which streamlines both standard and automated checkout processes. For example, Amazon’s Just Walk Out technology allows customers to pick up items and leave the store without traditional checkout, enhancing convenience and reducing wait times.
Retail operational excellence and cost optimization with Edge AI – Examples
Edge AI also significantly enhances operational efficiency, especially operational in-store efficiency, reduces losses, and helps lower costs (while at the same time enhancing sustainability):
Loss Prevention: Retail shrink, exacerbated by inflation-driven shoplifting and self-checkout vulnerabilities, costs the industry over $100 billion annually. Advanced sensors and intelligent cameras combined with Edge AI help detect early signs of theft or fraud. Thus, allowing security measures to intervene promptly, and independently from an internet connection.
Energy Savings: Smart sensors and Edge AI can be used to optimize the use of energy for lighting, heating, ventilation, water use, etc. For example, 45 Broadway, a 32-story office building in Manhattan, implemented an AI system that analyzes real-time data. That included temperature, humidity, sun angle, and occupancy patterns – to proactively adjust HVAC settings. This integration led to a 15.8% reduction in HVAC-related energy consumption. Plus, saving over $42,000 annually and reducing carbon emissions by 37 metric tons in just 11 months.
Conclusion: Edge AI as Retail’s Strategic Imperative
Yet, Edge AI isn’t just about running AI models locally. It’s about creating an autonomous, resilient system where on-device vector databases, local processing, and hybrid data sync work together. This combination enables real-time retail intelligence while keeping costs low, data private, and operations uninterrupted. To stay ahead, businesses should invest in edge-ready infrastructure with on-device vector databases and data sync that works on-premise at their core. Those who hesitate risk losing ground to nimble competitors who have already tapped into real-time, in-store intelligence.
Hybrid systems, combining lightning-fast offline-first edge response times with the power of the cloud, are becoming the norm. IDC projects that 78% of retailers will adopt these setups by 2026, saving an average of $3.6 million per store annually. In an inflation-driven market, Edge AI isn’t just a perk – it’s a critical strategy for thriving in the future of retail. By leveraging Edge AI-powered on-device databases, retailers gain the speed, efficiency, and reliability needed to stay competitive in an AI-driven retail landscape.
Can Small Language Models (SLMs) really do more with less? In this article, we discuss the unique strengths of SLMs, learn about the top SLMs, local vector databases, and how SLMs + local vector databases are shaping the future of AI,prioritizing privacy, immediacy, and sustainability.
Now, Small Language Models (SLMs) are stepping into the spotlight, enabling sophisticated AI to run directly on devices (local AI) like your phone, laptop, or even a smart home assistant. These models not only reduce costs and energy consumption but also bring the power of AI closer to the user, ensuring privacy and real-time performance.
What Are Small Language Models (SLMs)?
LLMs are designed to understand and generate human language. Small Language Models (SLMs) are compact versions of LLMs. So, the key difference between SLMs and LLMs is their size. While LLMs like GPT-4 are designed with hundreds of billions of parameters, SLMs use only a fraction of that. There is no strict definition of SLM vs. LLM yet. At this moment, SLM sizes can be as small as single-digit million parameters and go up to several billion parameters. Some authors suggest 8B parameters as the limit for SLMs. However, in our view that opens up the question if we need a definition for Tiny Language Models (TLMs)?
Advantages and disadvantages of SLM
According to Deloitte’s latest tech trends report, SLMs are gaining increasing importance in the AI landscape due to their cost-effectiveness, efficiency, and privacy advantages. Small Language Models (SLMs) bring a range of benefits, particularly for local AI applications, but they also come with trade-offs.
Benefits of SLMs
Privacy: By running on-device, SLMs keep sensitive information local, eliminating the need to send data to the cloud.
Offline Capabilities: Local AI powered by SLMs functions seamlessly without internet connectivity.
Speed: SLMs require less computational power, enabling faster inference and smoother performance.
Sustainability: With lower energy demands for both training and operation, SLMs are more environmentally friendly.
Accessibility: Affordable training and deployment, combined with minimal hardware requirements, make SLMs accessible to users and businesses of all sizes.
Limitations of SLMs
The main disadvantage is the flexibility and quality of SLM responses: SLMs typically cannot tackle the same broad range of tasks as LLMs in the same quality. However, in certain areas, they already match their larger counterparts. For example, Artificial Analysis AI Review 2024 highlights that GPT-4o-mini (July 2024) has a similar Quality Index to GPT-4 (March 2023), while being 100x cheaper in price.
Small Language Models vs LLMs
A recent study comparing various SLMs highlights the growing competitiveness of these models, demonstrating that in specific tasks, SLMs can achieve performance levels comparable to much larger models.
Overcoming limitations of SLMs
A combination of SLMs with local vector databases is a game-changer. With a local vector database, the variety of tasks and the quality of answers cannot only be enhanced but also for the areas that are actually relevant to the use case you are solving. E.g. you can add internal company knowledge, specific product manuals, or personal files to the SLM. In short, you can provide the SLM with context and additional knowledge that has not been part of its training via a local vector database. In this combination, an SLM can already today be as powerful as an LLM for your specific case and context (your tasks, your apps, your business). We’ll dive into this a bit more later.
In the following, we’ll have a look at the current landscape of SLMs – including the top SLMs – in a handy comparison matrix.
"The Gemma performs well on the Open LLM leaderboard. But if we compare Gemma-2b (2.51 B) with PHI-2 (2.7 B) on the same benchmarks, PHI-2 easily beats Gemma-2b."
iPhone 14: Phi-3-mini processing speed of 12 tokens per second. From the H2O Danube3 benchmarks you can see that the Phi-3 model shows top performance compared to similar size models, oftentimes beating the Danube3
OpenELM
270M, 450M, 1.1B, 3B
Apple
Apple License, but pretty much reads like you can do as much with it as a permissive oss license (of course not use their logo)
OpenELM 1.1 B shows 1.28% (Zero Shot Tasks), 2.36% (OpenLLM Leaderboard), and 1.72% (LLM360) higher accuracy compared to OLMo 1.2 B, while using 2× less pretraining data
"competitive performance compared to popular models of similar size across a wide variety of benchmarks including academic benchmarks, chat benchmarks, as well as fine-tuning benchmarks"
GPT-4o mini scores 82% on MMLU and currently outperforms GPT-4 on chat preferences in LMSYS leaderboard. GPT-4o mini surpasses GPT-3.5 Turbo and other small models on academic benchmarks across both textual intelligence and multimodal reasoning, and supports the same range of languages as GPT-4o
Smaller and faster variant of 1.5 Flash features half the price, twice the rate limits, and lower latency on small prompts compared to its forerunner. Nearly matches 1.5 Flash on many key benchmarks.
MMLU score of 69.4% and a Quality Index across evaluations of 53. Faster compared to average, with a output speed of 157.7 tokens per second. Low latency (0.37s TTFT), small context window (128k).
MMLU score 60.1%. Mistral 7B significantly outperforms Llama 2 13B on all metrics, and is on par with Llama 34B (since Llama 2 34B was not released, we report results on Llama 34B). It is also vastly superior in code and reasoning benchmarks. Was the best model for its size in autumn 2023.
Claimed (by Mistral) to be the world's best Edge models.
Ministral 3B has MMLU score of 58% and Quality index across evaluations of 51. Ministral 8B has MMLU score of 59% and Quality index across evaluations of 53.
Granite 3.0 8B Instruct matches leading similarly-sized open models on academic benchmarks while outperforming those peers on benchmarks for enterprise tasks and safety.
Quality Index across evaluations of 77, MMLU 85%, Supports a 16K token context window, ideal for long-text processing. Outperforms Phi3 and outperforms on many metrices or is comparable with Qwen 2.5 , and GPT-4o-mini
SLM Use Cases – best choice for running local AI
SLMs are perfect for on-device or local AI applications. On-device / local AI is needed in scenarios that involve hardware constraints, demand real-time or guaranteed response rates, require offline functionality or need to comply with strict data privacy and security needs. Here are some examples:
Mobile Applications: Chatbots or translation tools that work seamlessly on phones even when not connected to the internet.
IoT Devices: Voice assistants, smart appliances, and wearable tech running language models directly on the device.
Healthcare: Embedded in medical devices, SLMs allow patient data to be analyzed locally, preserving privacy while delivering real-time diagnostics.
Industrial Automation: SLMs process language on edge devices, increasing uptime and reducing latency in robotics and control systems.
By processing data locally, SLMs not only enhance privacy but also ensure reliable performance in environments where connectivity may be limited.
On-device Vector Databases and SLMs: A Perfect Match
Imagine a digital assistant on your phone that goes beyond generic answers, leveraging your company’s (and/or your personal) data to deliver precise, context-aware responses – without sharing this private data with any cloud or AI provider. This becomes possible when Small Language Models are paired with local vector databases. Using a technique called Retrieval-Augmented Generation (RAG), SLMs access the additional knowledge stored in the vector database, enabling them to provide personalized, up-to-date answers. Whether you’re troubleshooting a problem, exploring business insights, or staying informed on the latest developments, this combination ensures tailored and relevant responses.
Key Benefits of using a local tech stack with SLMs and a local vector database
Privacy. SLMs inherently provide privacy advantages by operating on-device, unlike larger models that rely on cloud infrastructure. To maintain this privacy advantage when integrating additional data, a local vector database is essential. ObjectBox is a leading example of a local database that ensures sensitive data remains local.
Personalization. Vector databases give you a way to enhance the capabilities of SLMs and adapt them to your needs. For instance, you can integrate internal company data or personal device information to offer highly contextualized outputs.
Quality. Using additional context-relevant knowledge reduces hallucinations and increases the quality of the responses.
Traceability. As long as you store your metadata alongside the vector embeddings, all the knowledge you use from the local vector database can give the sources.
Offline-capability. Deploying SLMs directly on edge devices removes the need for internet access, making them ideal for scenarios with limited or no connectivity.
Cost-Effectiveness. By retrieving and caching the most relevant data to enhance the response of the SLM, vector databases reduce the workload of the SLM, saving computational resources. This makes them ideal for edge devices, like smartphones, where power and computing resources are limited.
Use case: Combining SLMs and local Vector Databases in Robotics
Imagine a warehouse robot that organizes inventory, assists workers, and ensures smooth operations. By integrating SLMs with local vector databases, the robot can process natural language commands, retrieve relevant context, and adapt its actions in real time – all without relying on cloud-based systems.
For example:
A worker says, “Can you bring me the red toolbox from section B?”
The SLM processes the request and consults the vector database, which stores information about the warehouse layout, inventory locations, and specific task history.
Using this context, the robot identifies the correct toolbox, navigates to section B, and delivers it to the worker.
The future of AI is – literally – in our hands
AI is becoming more personal, efficient, and accessible, and Small Language Models are driving this transformation. By enabling sophisticated local AI, SLMs deliver privacy, speed, and adaptability in ways that larger models cannot. Combined with technologies like vector databases, they make it possible to provide affordable, tailored, real-time solutions without compromising data security. The future of AI is not just about doing more – it’s about doing more where it matters most: right in your hands.
After 6 years and 21 incremental “zero dot” releases, we are excited to announce the first major release of ObjectBox, the high-performance embedded database for C++ and C. As a faster alternative to SQLite, ObjectBox delivers more than just speed – it’s object-oriented, highly efficient, and offers advanced features like data synchronization and vector search. It is the perfect choice for on-device databases, especially in resource-constrained environments or in cases with real-time requirements.
What is ObjectBox?
ObjectBox is a free embedded database designed for object persistence. With “object” referring to instances of C++ structs or classes, it is built for objects from scratch with zero overhead — no SQL or ORM layer is involved, resulting in outstanding object performance.
The ObjectBox C++ database offers advanced features, such as relations and ACID transactions, to ensure data consistency at all times. Store your data privately on-device across a wide range of hardware, from low-profile ARM platforms and mobile devices to high-speed servers. It’s a great fit for edge devices, iOS or Android apps, and server backends. Plus, ObjectBox is multi-platform (any POSIX will do, e.g. iOS, Android, Linux, Windows, or QNX) and multi-language: e.g., on mobile, you can work with Kotlin, Java or Swift objects. This cross-platform compatibility is no coincidence, as ObjectBox Sync will seamlessly synchronize data across devices and platforms.
Why should C and C++ Developers care?
ObjectBox deeply integrates with C and C++. Persisting C or C++ structs is as simple as a single line of code, with no need to interact with unfamiliar database APIs that disrupt the natural flow of C++. There’s also no data transformation (e.g. SQL, rows & columns) required, and interacting with the database feels seamless and intuitive.
As a C or C++ developer, you likely value performance. ObjectBox delivers exceptional speed (at least we haven’t tested against a faster DB yet). Having several 100,000s CRUD operations per second on commodity hardware is no sweat. Our unique advantage is that, if you want to, you can read raw objects from “mmapped” memory (directly from disk!). This offers true “zero copy” data access without any throttling layers between you and the data.
Finally, CMake support makes integration straightforward, starting with FetchContent support so you can easily get the library. But there’s more: we offer code generation for entity structs, which takes only a single CMake command.
“ObjectBox++”: A quick Walk-Through
Once ObjectBox is set up for CMake, the first step is to define the data model using FlatBuffers schema files. FlatBuffers is a building block within ObjectBox and is also widely used in the industry. For those familiar with Protocol Buffers, FlatBuffers are its parser-less (i.e., faster) cousin. Here’s an example of a “Task” entity defined in a file named “task.fbs”:
1
2
3
4
tableTask{
id:ulong;
text:string;
}
And with that file, you can generate code using the following CMake command:
Among other things, code generation creates a C++ struct for Task data, which is used to interact with the ObjectBox API. The struct is a straightforward C++ representation of the data model:
1
2
3
4
structTask{
obx_id id;// uint64_t
std::stringtext;
};
The code generation also provides some internal “glue code” including the method create_obx_model() that defines the data model internally. With this, you can open the store and insert a task object in just three lines of code:
1
2
3
obx::Store store(create_obx_model());// Create the database
obx::Box<Task>box(store);// Main API for a type
obx_id id=box.put({.text="Buy milk"});// Object is persisted
And that’s all it takes to get a database running in C++. This snippet essentially covers the basics of the getting started guide and this example project on GitHub.
Vector Embeddings for C++ AI Applications
Even if you don’t have an immediate use case, ObjectBox is fully equipped for vectors and AI applications. As a “vector database,” ObjectBox is ready for use in high-dimensional vector similarity searches, employing the HNSW algorithm for highly scalable performance beyond millions of vectors.
Vectors can represent semantics within a context (e.g. objects in a picture) or even documents and paragraphs to “capture” their meaning. This is typically used for RAG (Retrieval-Augmented Generation) applications that interact with LLMs. Basically, RAG allows AI to work with specific data, e.g. documents of a department or company and thus individualizes the created content.
To quickly illustrate vector search, imagine a database of cities including their location as a 2-dimensional vector. To enable nearest neighbor search, all you need to do is to define a HNSW index on the location property, which enables the nearestNeighbors query condition used like this:
This release marks an important milestone for ObjectBox, delivering significant improvements in speed, usability, and features. We’re excited to see how these enhancements will help you create even better, feature-rich applications.
As always, we’re here to listen to your feedback and are committed to continually evolving ObjectBox to meet your needs. Don’t hesitate to reach out to us at any time.
P.S. Are you looking for a new job? We have a vacant C++ position to build the future of ObjectBox with us. We are looking forward to receiving your application! 🙂
As artificial intelligence (AI) continues to evolve, companies, researchers, and developers are recognizing that bigger isn’t always better. Therefore, the era of ever-expanding model sizes is giving way to more efficient, compact models, so-called Small Language Models (SLMs). SLMs offer several key advantages that address both the growing complexity of AI and the practical challenges of deploying large-scale models. In this article, we’ll explore why the race for larger models is slowing down and how SLMs are emerging as the sustainable solution for the future of AI.
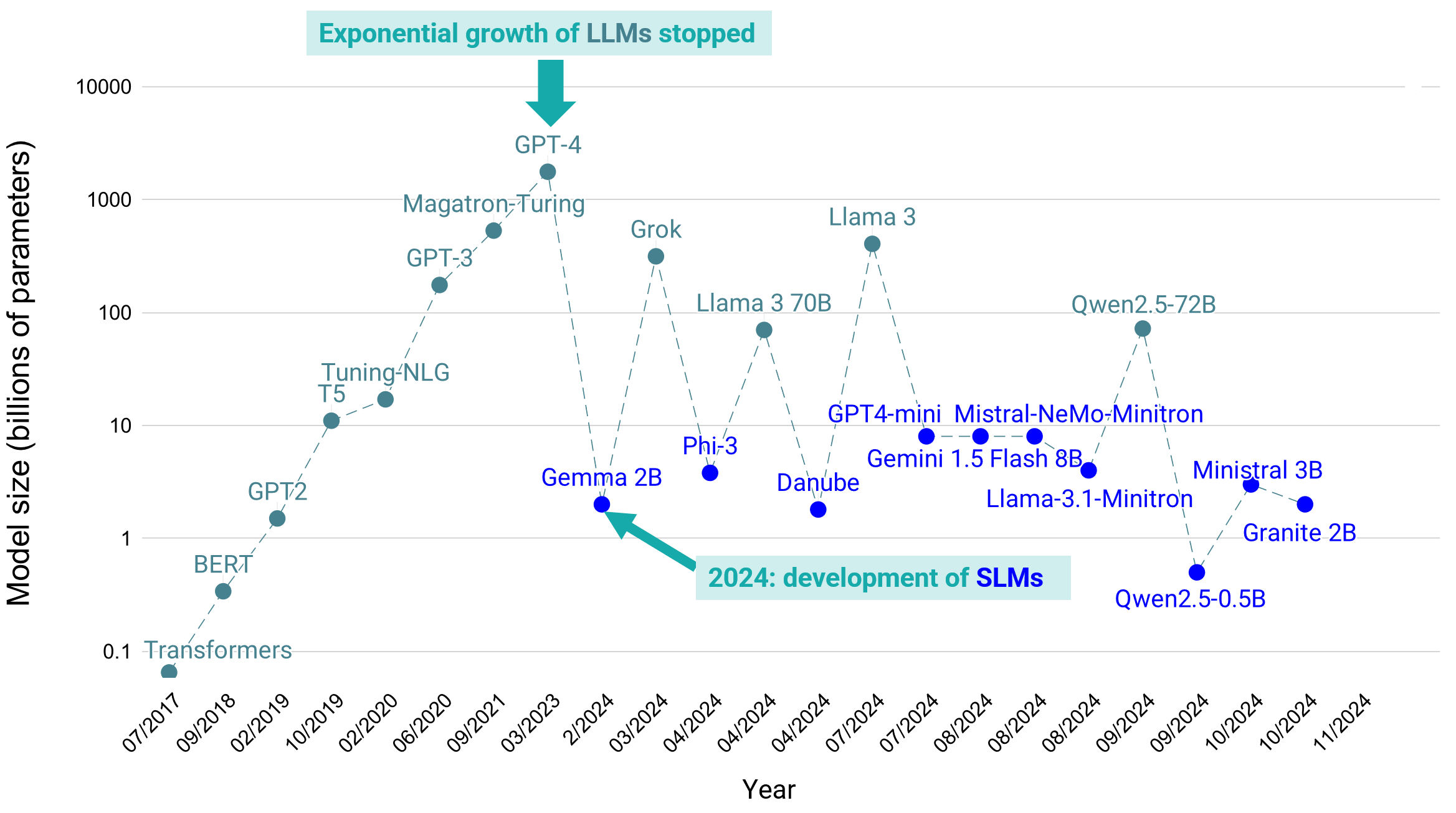
From Bigger to Better: The End of the Large Model Race
Up until 2023, the focus was on expanding models to unprecedented scales. But the era of creating ever-larger models appears to be coming to an end. Many newer models like Grok or Llama 3 are smaller in size yet maintain or even improve performance compared to models from just a year ago. The drive now is to reduce model size, optimize resources, and maintain power.
The Plateau of Large Language Models (LLMs)
Why Bigger No Longer Equals Better
As models become larger, developers are realizing that the performance improvements aren’t always worth the additional computational cost. Breakthroughs in knowledge distillation and fine-tuning enable smaller models to compete with and even outperform their larger predecessors in specific tasks. For example, medium-sized models like Llama with 70B parameters and Gemma-2 with 27B parameters are among the top 30 models in the chatbot arena, outperforming even much larger models like GPT-3.5 with 175B parameters.
The Shift Towards Small Language Models (SLMs)
In parallel with the optimization of LLMs, the rise of SLMs presents a new trend (see Figure). These models require fewer computational resources, offer faster inference times, and have the potential to run directly on devices. In combination with an on-device database, this enables powerful local GenAI and on-device RAG apps on all kinds of embedded devices, like on mobile phones, Raspberry Pis, commodity laptops, IoT, and robotics.
Advantages of SLMs
Despite the growing complexity of AI systems, SLMs offer several key advantages that make them essential in today’s AI landscape:
Accessibility As SLMs are less resource-hungry (less hardware requirements, less CPU, memory, power needs), they are more accessible for companies and developers with smaller budgets. Because the model and data can be used locally, on-device / on-premise, there is no need for cloud infatstructure and they are also usable for use cases with high privacy requirements. All in all, SLMs democratize AI development and empower smaller teams and individual developers to deploy advanced models on more affordable hardware.
Cost Reduction and Sustainability Training and deploying large models require immense computational and financial resources, and comes with high operational costs. SLMs drastically reduce the cost of training, deployment, and operation as well as the carbon footprint, making AI more financially and environmentally sustainable.
On-Device AI for Privacy and Security SLMs are becoming compact enough for deployment on edge devices like smartphones, IoT sensors, and wearable tech. This reduces the need for sensitive data to be sent to external servers, ensuring that user data stays local. With the rise of on-device vector databases, SLMs can now handle use-case-specific, personal, and private data directly on the device. This allows more advanced AI apps, like those using RAG, to interact with personal documents and perform tasks without sending data to the cloud. With a local, on-device vector database users get personalized, secure AI experiences while keeping their data private.
The Future: Fit-for-Purpose Models: From Tiny to Small to Large Language models
The future of AI will likely see the rise of models that are neither massive nor minimal but fit-for-purpose. This “right-sizing” reflects a broader shift toward models that balance scale with practicality. SLMs are becoming the go-to choice for environments where specialization is key and resources are limited. Medium-sized models (20-70 billion parameters) are becoming the standard choice for balancing computational efficiency and performance on general AI tasks. At the same time, SLMs are proving their worth in areas that require low latency and high privacy.
Innovations in model compression, parameter-efficient fine-tuning, and new architecture designs are enabling these smaller models to match or even outperform their predecessors. The focus on optimization rather than expansion will continue to be the driving force behind AI development in the coming years.
Conclusion: Scaling Smart is the New Paradigm
As the field of AI moves beyond the era of “bigger is better,” SLMs and medium-sized models are becoming more important than ever. These models represent the future of scalable and efficient AI. They serve as the workhorses of an industry that is looking to balance performance with sustainability and efficiency. The focus on smaller, more optimized models demonstrates that innovation in AI isn’t just about scaling up; it’s about scaling smart.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.


 in 2026")