
First on-device Vector Database (aka Semantic Index) for iOS
Easily empower your iOS and macOS apps with fast, private, and sustainable AI features. All you need is a Small Language Model (SLM; aka “small LLM”) and ObjectBox – our on-device vector database built for Swift apps. This gives you a local semantic index for fast on-device AI features like RAG or GenAI that run without an internet connection and keep data private.
The recently demonstrated “Apple Intelligence” features are precisely that: a combination of on-device AI models and a vector database (semantic index). Now, ObjectBox Swift enables you to add the same kind of AI features easily and quickly to your iOS apps right now.
Not developing with Swift? We also have a Flutter / Dart binding (works on iOS, Android, desktop), a Java / Kotlin binding (works on Android and JVM), or one in C++ for embedded devices.
Enabling Advanced AI Anywhere, Anytime
Typical AI apps use data (e.g. user-specific data, or company-specific data) and multiple queries to enhance and personalize the quality of the model’s response and perform complex tasks. And now, for the very first time, with the release of ObjectBox 4.0, this will be possible locally on restricted devices.
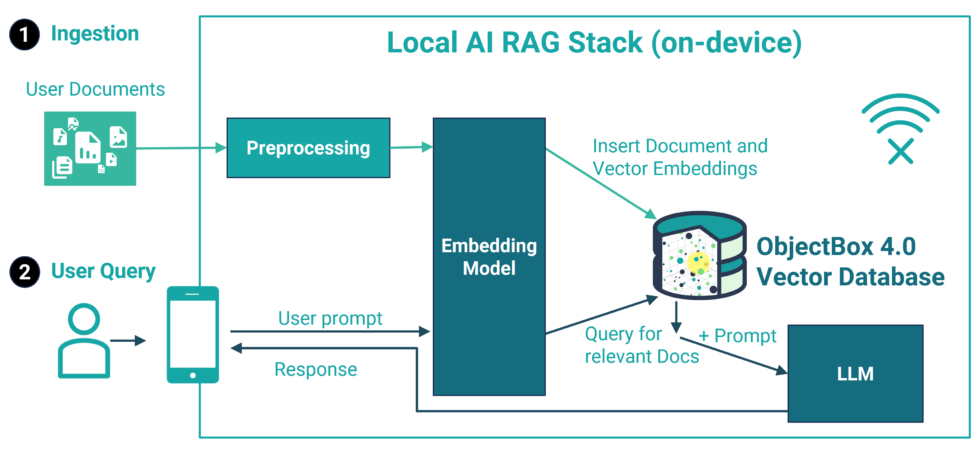 Local AI Tech Stack Example for on-device RAG
Local AI Tech Stack Example for on-device RAG
Swift on-device Vector Database and search for iOS and MacOS
With the ObjectBox Swift 4.0 release, it is possible to create a scalable vector index on floating point vector properties. It’s a very special index that uses an algorithm called HNSW. It’s scalable because it can find relevant data within millions of entries in a matter of milliseconds.
Let’s pick up the cities example from our vector search documentation. Here, we use cities with a location vector and want to find the closest cities (a proximity search). The Swift class for the City entity shows how to define an HNSW index on the location:
|
1 2 3 4 5 6 7 8 9 10 |
// objectbox: entity class City { var id: Id = 0 var name: String? // objectbox:hnswIndex: dimensions=2 var location: [Float]? } </code><!-- wp:paragraph --><!-- /wp:preformatted --> |
Inserting City objects with a float vector and HNSW index works as usual, the indexing happens behind the scenes:
|
1 2 3 4 5 6 7 |
let box: Box<city> = store.box() try box.put([ City("Barcelona", [41.385063, 2.173404]), City("Nairobi", [-1.292066, 36.821945]), City("Salzburg", [47.809490, 13.055010]), ]) </city></code><!-- wp:paragraph --><!-- /wp:html --> |
To then find cities closest to a location, we do a nearest neighbor search using the new query condition and “find with scores” methods. The nearest neighbor condition accepts a query vector, e.g. the coordinates of Madrid, and a count to limit the number of results of the nearest neighbor search, here we want at max 2 cities. The find with score methods are like a regular find, but in addition return a score. This score is the distance of each result to the query vector. In our case, it is the distance of each city to Madrid.
|
1 2 3 4 5 6 7 8 9 10 11 12 |
let madrid = [40.416775, -3.703790] // query vector // Prepare a Query object to search for the 2 closest neighbors: let query = try box .query { City.location.nearestNeighbors(queryVector: madrid, maxCount: 2) } .build() let results = try query.findWithScores() for result in results { print("City: \(result.object.name), distance: \(result.score)") } |
The ObjectBox on-device vector database empowers AI models to seamlessly interact with user-specific data — like texts and images — directly on the device, without relying on an internet connection. With ObjectBox, data never needs to leave the device, ensuring data privacy.
Thus, it’s the perfect solution for developers looking to create smarter apps that are efficient and reliable in any environment. It enhances everything from personalized banking apps to robust automotive systems.
ObjectBox: Optimized for Resource Efficiency
At ObjectBox, we specialize on efficiency that comes from optimized code. Our hearts beat for creating highly efficient and capable software that outperforms alternatives on small and big hardware. ObjectBox maximizes speed while minimizing resource use, extending battery life, and reducing CO2 emissions.
With this expertise, we took a unique approach to vector search. The result is not only a vector database that runs efficiently on constrained devices but also one that outperforms server-side vector databases (see first benchmark results; on-device benchmarks coming soon). We believe this is a significant achievement, especially considering that ObjectBox still upholds full ACID properties (guaranteeing data integrity).
 Cloud/server vector databases vs. On-device/Edge vector databases
Cloud/server vector databases vs. On-device/Edge vector databasesAlso, keep in mind that ObjectBox is a fully capable database. It allows you to store complex data objects along with vectors. Thus, you have the full feature set of a database at hand. It empowers hybrid search, traceability, and powerful queries.
Use Cases / App ideas
ObjectBox can be used for a million different things, from empowering generative AI features in mobile apps to predictive maintenance on ECUs in cars to AI-enhanced games. For iOS apps, we expect to see the following on-device AI use cases very soon:
- Across all categories we’ll see Chat-with-files apps:
- Travel: Imagine chatting to your favorite travel guide offline, anytime, anywhere. No need to carry bulky paper books, or scroll through a long PDF on your mobile.
- Research: Picture yourself chatting with all the research papers in your field. Easily compare studies and findings, and quickly locate original quotes.

Chat-with-files apps (across verticals & categories)
- Travel: Imagine chatting to your favorite travel guide offline, anytime, anywhere. No need to carry bulky paper books, or scroll through a long PDF on your mobile
- Research: Picture yourself chatting with all the research papers in your field. Easily compare studies and findings, and quickly locate original quotes.
- Education: Educational apps featuring “chat-with-your-files” functionality for learning materials and research papers. But going beyond that, they generate quizzes and practice questions to help people solidify knowledge.
Lifestyle – from Coaching to Health
-
- Health: Apps offering personalized recommendations based on scientific research, your preferences, habits, and individual health data. This includes data tracked from your device, lab results, and doctoral diagnosis.

Productivity: Personal assistants for all areas of life
-
- Family Management: Interact with assistants tailored to specific roles. Imagine a parent’s assistant that monitors school channels, chat groups, emails, and calendars. Its goal is to automatically add events like school plays, remind you about forgotten gym bags, and even suggest birthday gifts for your child’s friends.
-
- Professional Assistants: Imagine being a busy sales rep on the go, juggling appointments and travel. A powerful on-device sales assistant can do more than just automation. It can prepare contextual and personalized follow-ups instantly. For example, by summarizing talking points, attaching relevant company documents, and even suggesting who to CC in your emails.
Run the local AI Stack with a Language Model (SLM, LLM)
Recent Small Language Models (SMLs) already demonstrate impressive capabilities while being small enough to run on e.g. mobile phones. To run the model on-device of an iPhone or a macOS computer, you need a model runtime. On Apple Silicone the best choice in terms of performance typically MLX – a framework brought to you by Apple machine learning research. It supports the hardware very efficiently by supporting CPU/GPU and unified memory.
To summarize, you need these three components to run on-device AI with an semantic index:
-
- ObjectBox: vector database for the semantic index
- Models: choose an embedding model and a language model to match your requirements
- MLX as the model runtime
Start building next generation on-device AI apps today! Head over to our vector search documentation and Swift documentation for details.









