As artificial intelligence (AI) continues to evolve, companies, researchers, and developers are recognizing that bigger isn’t always better. Therefore, the era of ever-expanding model sizes is giving way to more efficient, compact models, so-called Small Language Models (SLMs). SLMs offer several key advantages that address both the growing complexity of AI and the practical challenges of deploying large-scale models. In this article, we’ll explore why the race for larger models is slowing down and how SLMs are emerging as the sustainable solution for the future of AI.
From Bigger to Better: The End of the Large Model Race
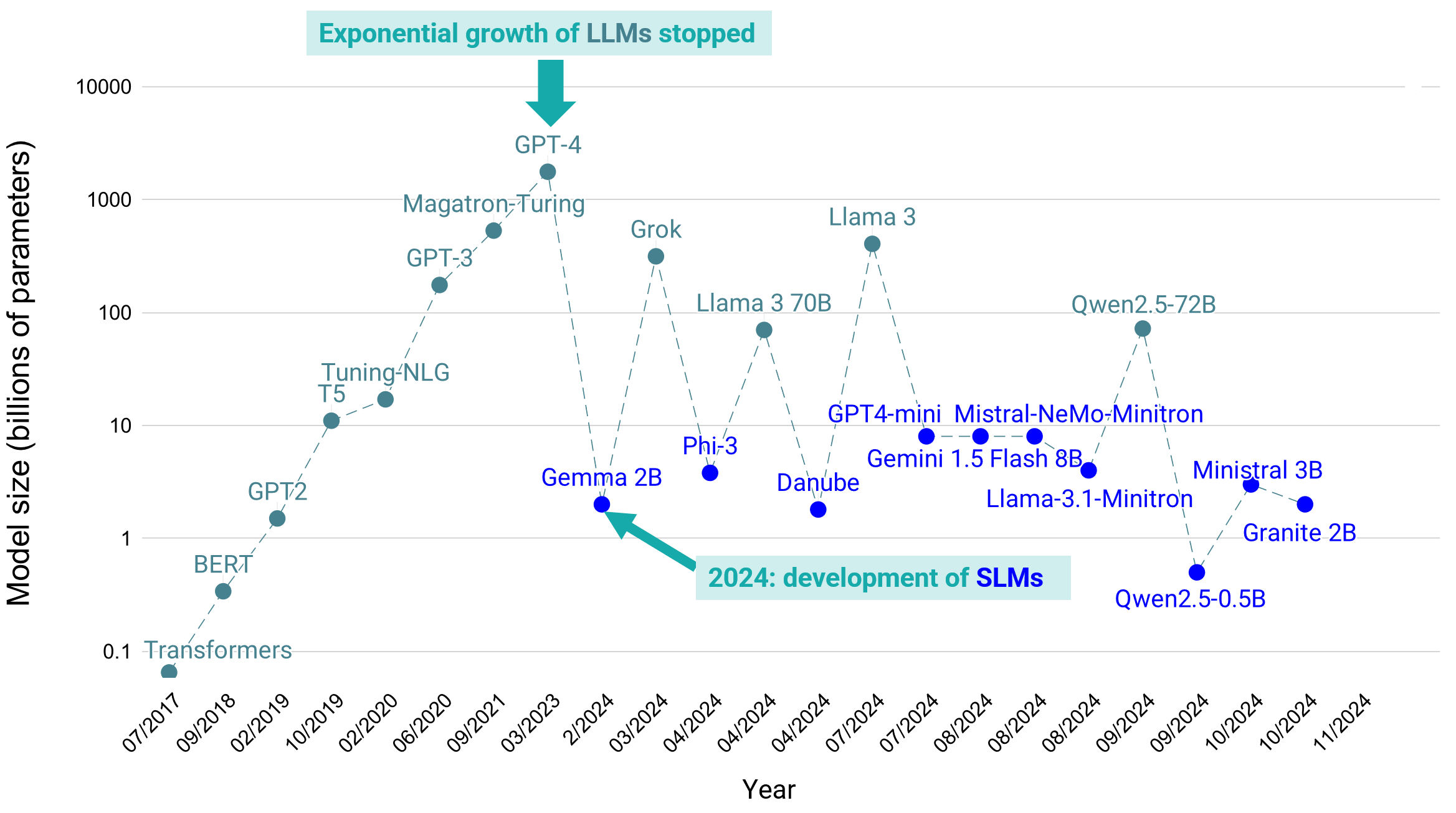
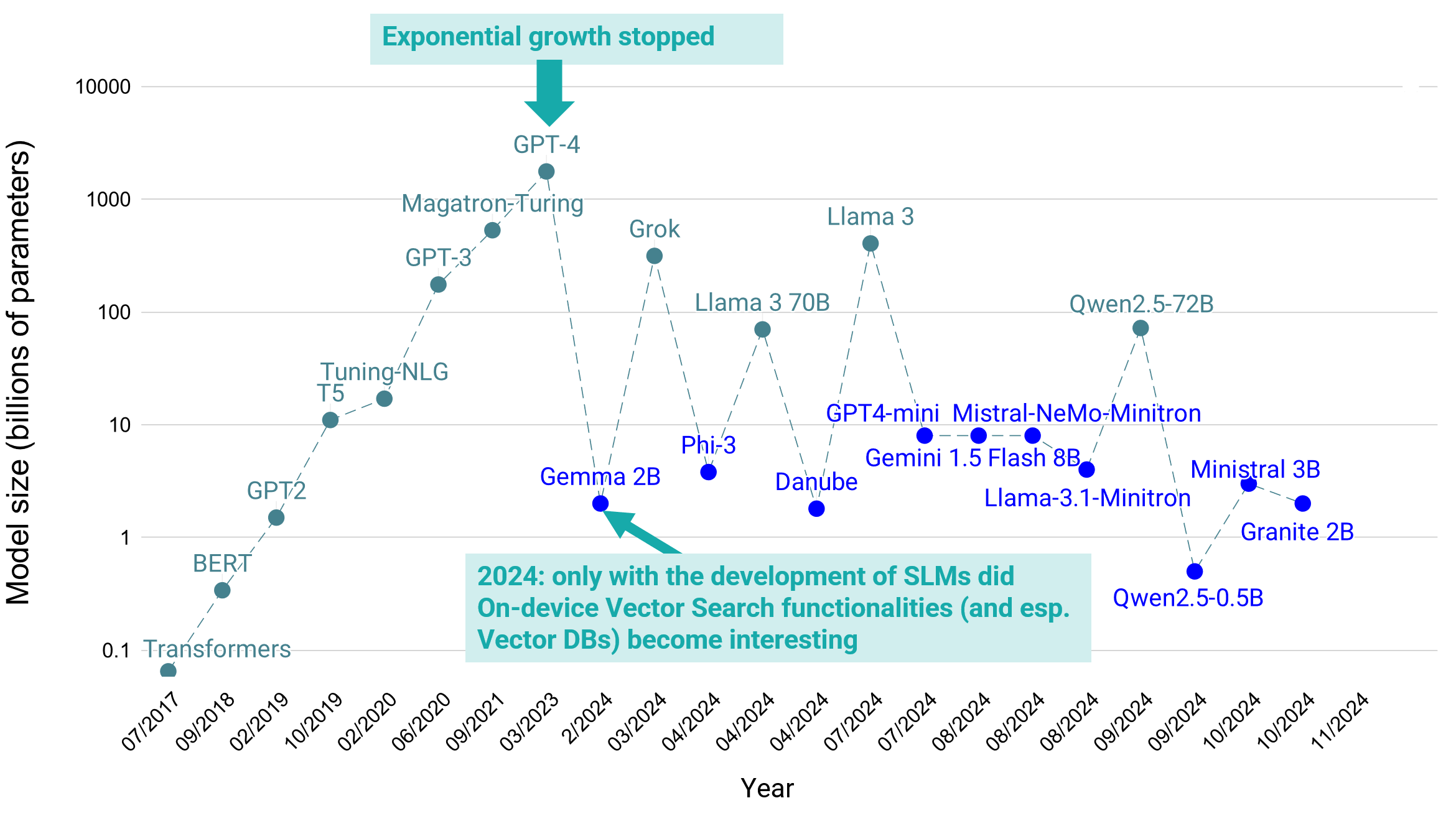
Up until 2023, the focus was on expanding models to unprecedented scales. But the era of creating ever-larger models appears to be coming to an end. Many newer models like Grok or Llama 3 are smaller in size yet maintain or even improve performance compared to models from just a year ago. The drive now is to reduce model size, optimize resources, and maintain power.
The Plateau of Large Language Models (LLMs)
Why Bigger No Longer Equals Better
As models become larger, developers are realizing that the performance improvements aren’t always worth the additional computational cost. Breakthroughs in knowledge distillation and fine-tuning enable smaller models to compete with and even outperform their larger predecessors in specific tasks. For example, medium-sized models like Llama with 70B parameters and Gemma-2 with 27B parameters are among the top 30 models in the chatbot arena, outperforming even much larger models like GPT-3.5 with 175B parameters.
The Shift Towards Small Language Models (SLMs)
In parallel with the optimization of LLMs, the rise of SLMs presents a new trend (see Figure). These models require fewer computational resources, offer faster inference times, and have the potential to run directly on devices. In combination with an on-device database, this enables powerful local GenAI and on-device RAG apps on all kinds of embedded devices, like on mobile phones, Raspberry Pis, commodity laptops, IoT, and robotics.
Advantages of SLMs
Despite the growing complexity of AI systems, SLMs offer several key advantages that make them essential in today’s AI landscape:
Accessibility As SLMs are less resource-hungry (less hardware requirements, less CPU, memory, power needs), they are more accessible for companies and developers with smaller budgets. Because the model and data can be used locally, on-device / on-premise, there is no need for cloud infatstructure and they are also usable for use cases with high privacy requirements. All in all, SLMs democratize AI development and empower smaller teams and individual developers to deploy advanced models on more affordable hardware.
Cost Reduction and Sustainability Training and deploying large models require immense computational and financial resources, and comes with high operational costs. SLMs drastically reduce the cost of training, deployment, and operation as well as the carbon footprint, making AI more financially and environmentally sustainable.
On-Device AI for Privacy and Security SLMs are becoming compact enough for deployment on edge devices like smartphones, IoT sensors, and wearable tech. This reduces the need for sensitive data to be sent to external servers, ensuring that user data stays local. With the rise of on-device vector databases, SLMs can now handle use-case-specific, personal, and private data directly on the device. This allows more advanced AI apps, like those using RAG, to interact with personal documents and perform tasks without sending data to the cloud. With a local, on-device vector database users get personalized, secure AI experiences while keeping their data private.
The Future: Fit-for-Purpose Models: From Tiny to Small to Large Language models
The future of AI will likely see the rise of models that are neither massive nor minimal but fit-for-purpose. This “right-sizing” reflects a broader shift toward models that balance scale with practicality. SLMs are becoming the go-to choice for environments where specialization is key and resources are limited. Medium-sized models (20-70 billion parameters) are becoming the standard choice for balancing computational efficiency and performance on general AI tasks. At the same time, SLMs are proving their worth in areas that require low latency and high privacy.
Innovations in model compression, parameter-efficient fine-tuning, and new architecture designs are enabling these smaller models to match or even outperform their predecessors. The focus on optimization rather than expansion will continue to be the driving force behind AI development in the coming years.
Conclusion: Scaling Smart is the New Paradigm
As the field of AI moves beyond the era of “bigger is better,” SLMs and medium-sized models are becoming more important than ever. These models represent the future of scalable and efficient AI. They serve as the workhorses of an industry that is looking to balance performance with sustainability and efficiency. The focus on smaller, more optimized models demonstrates that innovation in AI isn’t just about scaling up; it’s about scaling smart.
Now, let’s have a look at what ObjectBox can offer:
High-performance on-device database
ObjectBox is designed from the ground up for resource-efficiency and performance. It offers superfast database operations (CRUD: Create, Read, Update, Delete), often outperforming other database solutions, including Mongo Realm. However, we all know benchmarking is hard and it depends on the use case. So, check out our open-source benchmarks and make up your mind yourself.
Migration with native language APIs
While we do hope that our intuitive native-language APIs (Swift, Java/Kotlin, C/C++, Flutter / Dart, Python) and setup are straightforward and quick for anyone to adapt, we are also listening to you and willing to invest in making the migration easier. Reach out to us with your feedback.
Cross-Platform Support
Like Mongo Realm, ObjectBox supports any POSIX system, including Android, iOS, Linux, Windows, and MacOS. This cross-platform compatibility ensures that you can maintain a consistent data layer across all your applications.
Efficient Sync Solution
ObjectBox offers its own Data Sync (ObjectBox Sync), which provides reliable and efficient data syncing between devices and servers. This feature is the one you are looking for if you relied on Realm’s Device Sync capabilities. ObjectBox was built with Data Sync in mind. We do have a cluster-mode that has been heavily tested for efficiency and reliability by industrial customers. We can handle millions of concurrent connections while providing realtime synchronization.
Offline-First Approach
ObjectBox embraces an offline-first architecture, allowing your apps to work seamlessly without an internet connection. Data is stored locally and can be synced between devices when offline or synced back to, e.g., a cloud once a connection becomes available again, ensuring a smooth user experience in various network conditions.
Active Development and Support
Unlike MongoDB Realm Device Sync (Atlas Device Sync), which is now deprecated, ObjectBox is actively developed and supported. This means you’ll benefit from regular updates, bug fixes, and new features, ensuring your data management solution remains robust and up-to-date.
We recently extended our database to become the very first on-device vector database enabling on-device AI (e.g. RAG, genAI, more efficient AI) on Mobile, IoT, and other embedded devices, see the vector search docs here. While extending our offering to serve MongoDB Realm customers wanting to migrate is the priority now, we’ll be extending Data Sync to synchronize vector embeddings next year too.
Conclusion
As MongoDB Realm’s Device Sync reaches its end of life, now is the perfect time to explore alternatives that cannot only replace but potentially enhance your app’s data management capabilities. To learn more about how ObjectBox can help you transition from Realm, visit the ObjectBox docs or schedule a call.
Artificial Intelligence (AI) has become an integral part of our daily lives in recent years. However, it has been tied to running in huge, centralized cloud data centers. This year, “local AI”, also known as “on-device AI” or “Edge AI”, is gaining momentum. Local vector databases, efficient language models (so-called Small Language Models (SLMs)), and AI algorithms are becoming smaller, more efficient, and better. As a result, they can now run on a wide variety of devices, locally.
Figure 1. Evolution of language model’s size with time. Large language models (LLMs) are marked as celadon circles, and small language models (SLMs) as blue ones.
What is Local AI (on-device AI, Edge AI)?
Local AI refers to running AI applications directly on a device, locally, instead of relying on (distant) cloud servers. On-device AI works directly on commodity hardware (e.g. old PCs), consumer devices (e.g. smartphones, wearables), and other types of embedded devices (e.g. robots and point-of-sale (POS) systems used in shops and restaurants). As we see in Figure 2, interest in local Artificial Intelligence (terms: Edge AI, Local AI, on-device AI, and tiny ML) and in Vector Databases is surging. And for good reason.
Local AI, Edge AI, on-device AI, mobile AI on Google Trends (until Sep 2025)
Why use Local AI: Benefits
Local AI addresses many of the concerns and challenges of current cloud-based AI applications. Benefits of local AI are:
Accessibility – SLM trainings and model use are way more affordable, they can work on all kinds of hardware, and independently from an internet connection (offline), making AI truly accessible for everyone
Sustainability – AI consumes significantly less energy compared to cloud setups
On top, local AI reduces:
Latency, enabling real-time apps
data transmission and cloud costs, enabling commodity business cases
Local AI for Privacy: Keep Data Secure and Compliant with GDPR & HIPAA
In a world where data privacy concerns are increasing, local AI offers a solution. Since data is processed directly on the device, sensitive information remains local, minimizing the risk of breaches or misuse of personal data. No need for data sharing and data ownership is clear. This is the key to using AI responsibly in industries like healthcare, where sensitive data needs to be processed and used without being sent to external servers. For example, medical data analysis or diagnostic tools can run locally on a doctor’s device and be synchronized to other on-premise, local devices (like e.g. PCs, on-premise servers, specific medical equipment) as needed. This ensures that patient data never leaves the clinic, and data processing is compliant with strict privacy regulations like GDPR or HIPAA.
Local AI for Accessibility: AI for Anyone, Anytime
One of the most significant advantages of local AI is its ability to function without an internet connection. This opens up a world of opportunities for users in remote locations or those with unreliable connectivity. Imagine having access to language translation, image recognition, or predictive text tools on your phone without needing to connect to the internet. Or a point-of-sale (POS) system in a retail store that operates seamlessly, even when there’s no internet. These AI-powered systems can still analyze customer buying habits, manage inventory, or suggest product recommendations offline, ensuring businesses don’t lose operational efficiency due to connectivity issues. Local AI makes this a reality. In combination with little hardware requirements, it makes AI accessible to anyone, anytime. Therefore, local AI is an integral ingredient in making AI more inclusive and to democratize AI.
Local AI for Sustainability: Energy Efficiency
Cloud-based AI requires massive server farms that consume enormous amounts of energy. Despite strong efficiency improvements, in 2022, data centers globally consumed between 240 and 340 terawatt-hours (TWh) of electricity. To put this in perspective, data centers now use more electricity than entire countries like Argentina or Egypt. This growing energy demand places considerable pressure on global energy resources and contributes to around 1% of energy-related CO2 emissions.
The rise of AI has amplified these trends. According to McKinsey, the demand for data center capacity is projected to grow by over 20% annually, reaching approximately 300GW by 2030, with 70% of this capacity dedicated to hosting AI workloads. Gartner even predicts that by 2025, “AI will consume more energy than the human workforce”. AI workloads alone could drive a 160% increase in data center energy demand by 2030, with some estimates suggesting that AI could consume 500% more energy in the UK than it does today. By that time, data centers may account for up to 8% of total energy consumption in the United States.
In contrast, local AI presents a more sustainable alternative, e.g. by leveraging Small Language Models, which require less power to train and run. Since computations happen directly on the device, local AI significantly reduces the need for constant data transmission and large-scale server infrastructure. This not only lowers energy use but also helps decrease the overall carbon footprint. Additionally, integrating a local vector database can further enhance efficiency by minimizing reliance on power-hungry data centers, contributing to more energy-efficient and environmentally friendly technology solutions.
When to use Local AI / Edge AI: Use case examples
Local AI enables an infinite number of new use cases. Thanks to advancements in AI models and vector databases, AI apps can be run cost-effectively on less capable hardware, e.g. commodity PCs, without the need for an internet connection and data sharing. This opens up the opportunity for offline AI, real-time AI, and private AI applications on a wide variety of devices.
From smartphones and smartwatches to industrial equipment and even cars, local AI is becoming accessible to a broad range of users.
Consumer Use Cases (B2C): Everyday apps like photo editors, voice assistants, and fitness trackers can integrate AI to offer faster and more personalized services (local RAG), or integrate generative AI capabilities.
Business Use Cases (B2B): Retailers, manufacturers, and service providers can use local AI for data analysis, process automation, and real-time decision-making, even in offline environments. This improves efficiency and user experience without needing constant cloud connectivity.
Local AI / Edge AI B2B and B2C Use Cases
Conclusion
Local AI is a powerful alternative to cloud-based solutions, making AI more accessible, private, and sustainable. With Small Language Models and on-device vector databases like ObjectBox, it is now possible to bring AI onto everyday devices. From the individual user who is looking for convenient, always-available tools to large businesses seeking to improve operations and create new services without relying on the cloud – local AI is transforming how we interact with technology everywhere.
SQLite and SQLite alternatives - databases for the Mobile and IoT edge
Overview of SQLite and SQLite alternatives as part of the mobile / edge database market with a comprehensive comparison matrix (last updated autumn 2024)
Therefore, there is a renewed need for on-device databases like SQLite and SQLite alternatives to persist and manage data on edge devices. On top, due to the distributed nature of the edge, there is a need to manage data flows to / from and between edge devices. This can be done withEdge Databases that provide a Data Sync functionality (SQLite alternatives only, as SQLite doesn’t support this). Below, we’ll take a close look at SQLite and its alternatives with consideration of today’s needs.
Databases for the Edge
While being quite an established market with many players, the database market is still growing consistently and significantly. The reason is that databases are at the core of almost any digital solution, and directly impact business value and therefore never going out of fashion. With the rapid evolvements in the tech industry, however, databases evolve too. This, in turn, yields new database types and categories. We have seen the rise of NoSQL databases in the last 20 years, and more recently some novel database technologies, like graph databases and time-series databases, and vector databases.
With AI and accordingly vector databases being all the hype since 2022/2023, the database market is indeed experiencing fresh attention. Due to the speed with which AI is evolving, we’re however already leaving the “mainframe era of AI” and entering the distributed Edge AI space. With SQLite not supporting vector search and related vector database functions, this adds a new dimension to this ever-present topic. There is a need for local, on-device vector databases to support on-device AI that’s independent of an Internet connection, reliably fast, and keeps data on the device (100% private).
Both, the shift back from a centralised towards a decentralised paradigm, and the growing number of restricted devices call for a “new type” of an established database paradigm. SQLite has been around for more than 20 years and for good reason, but the current market shift back to decentralized computing happens in a new environment with new requirements. Hence, the need for a “new” database type, based on a well-established database type: “Edge databases”. Accordingly, a need for SQLite alternatives that consider the need for decentralized data flows and AI functionalities (depending on the use case of course; after all SQLite is a great database).
What is an Edge Database?
Edge databases are a type of databases that are optimised for local data storage on restricted devices, like embedded devices, Mobile, and IoT. Because they run on-device, they need to be especially resource-efficient (e.g. with regards to battery use, CPU consumption, memory, and footprint). The term “edge database” is becoming more widely-used every year, especially in the IoT industry. In IoT, the difference between cloud-based databases and ones that run locally (and therefore support Edge Computing) is crucial.
What is a Mobile Database?
We look at mobile databases as a subset of edge databases that run on mobile devices. The difference between the two terms lies mainly in the supported operating systems / types of devices. Unless Android and iOS are supported, an edge database is not really suited for the mobile device / smartphone market. In this article, we will use the term “mobile database” only as “database that runs locally on a mobile (edge) device and stores data on the device”. Therefore, we also refer to it as an “on-device” database.
What are the advantages and disadvantages of working with SQLite?
SQLite is a relational database that is clearly the most established database suitable to run on edge devices. Moreover, it is probably the only “established” mobile database. It was designed in 2000 by Richard Hipp and has been embedded with iOS and Android since the beginning. Now let’s have a quick look at its main advantages and disadvantages:
Advantages
Disadvantages
20+ years old (should be stable ;))
Toolchain, e.g. DB browser
No dependencies, is included with Android and iOS
Developers can define exactly the data schema they want
Full control, e.g. handwritten SQL queries
SQL is a powerful and established query language, and SQLite supports most of it
Debuggable data: developers can grab the database file and analyse it
20+ years old ( less state-of-the-art tech)
Using SQLite means a lot of boilerplate code and thus inefficiencies ( maintaining long running apps can be quite painful)
No compile time checks (e.g. SQL queries)
SQL is another language to master, and can impact your app’s efficiency / performance significantly…
The performance of SQLite is unreliable
SQL queries can get long and complicated
Testability (how to mock a database?)
Especially when database views are involved, maintainability may suffer with SQLite
What are the SQLite alternatives?
There are a bunch of options for making your life easier, if you want to use SQLite. You can use an object abstraction on top of it, an object-Relational-Mapper (ORM), for instance greenDAO, to avoid writing lots of SQL. However, you will typically still need to learn SQL and SQLite at some point. So what you really want is a full blown database alternative, like any of these: Couchbase Lite, Interbase, LevelDB, ObjectBox, Oracle Berkeley DB, Mongo Realm, SnappyDB, SQL Anywhere, or UnQLite.
While SQLite really is designed for small devices, people do run it on the server / cloud too. Actually, any database that runs efficiently locally, will be highly efficient on big servers too, making them a sustainable lightweight choice for some scenarios. However, for server / cloud databases, there are a lot of alternatives you can use as a replacement like e.g. MySQL, MongoDB, or Cloud Firestore.
Bear in mind that, if you are looking to host your database in the cloud with apps running on small distributed devices (e.g. mobile apps, IoT apps, any apps on embedded devices etc.), there are some difficulties. Firstly, this will result in higher latency, i.e. slow response-rates. Secondly, the offline capabilities will be highly limited or absent. As a result, you might have to deal with increased networking costs, which is not only reflected in dollars, but also CO2 emissions. On top, it means all the data from all the different app users is stored in one central place. This means that any kind of data breach will affect all your and your users’ data. Most importantly, you will likely be giving your cloud / database provider rights to that data. (Consider reading the general terms diligently). If you care about privacy and data ownership, you might therefore want to consider a local database option, as in an Edge Database. This way you can decide, possibly limit, what data you sync to a central instance (like the cloud or an on-premise server).
SQLite alternatives Comparison Matrix
To give you an overview, we have compiled a comparison table including SQLite and SQLite alternatives. In this matrix we look at databases that we believe are apt to run on edge devices. Our rule of thumb is the databases’ ability to run on Raspberry Pi type size devices. If you’re reading this on mobile, click here to view the full matrix.
Edge
Database
Short description
License / business model
Android / iOS*
Type of data stored
Central Data Sync
P2P Data Sync
Offline Sync (Edge)
Data level encryption
Flutter / Dart support
Vector Database (AI support)
Minimum Footprint size
Company
SQLite
C programming library;
probably still 90% market share in the small devices space (personal
assumption)
Embedded / portable database
with P2P and central synchronization (sync) support; pricing upon
request; some restrictions apply for the free version. Secure SSL.
Partly proprietary, partly
open-source, Couchbase Lite is BSL 1.1
Is there anything we’ve missed? What do you agree and disagree with? Please share your thoughts with us via Twitter or email us on contact[at]objectbox.io.
AI anywhere and anytime - free from Internet dependencies & 100% private
Edge AI is an often overlooked aspect of AI’s natural evolution. It is basically the move of AI functionalities away from the cloud (or powerful server infrastructure) towards decentralized (typically less powerful) devices at the network’s edges, including on mobile phones, smartwatches, IoT devices, microcontrollers, ECUs, or simply your local computer. Or in more broadly speaking: “Edge AI” means AI that works directly on-device, “local AI“.
Therefore, Edge AI apps work independently from an internet connection, offline as well as online. So, they are ideal for low, intermittent, or no connectivity scenarios. They are reliably available, more sustainable, and – of course – way faster on-device than anything hosted in the cloud. On-device AI apps can empower realtime AI anytime and anyplace.
The importance of vector databases for AI applications
To enable powerful on-device AI applications, the on-device (edge) technology stack needs local vector databases. So, before diving deeper into Edge AI, we’ll dive into vector databases first. Jump this section, if you are already familiar with them.
What is a vector database?
Just as SQL databases handle data in rows and columns, graph databases manage graphs, object databases store objects, vector databases store and manage large data sets of vectors, or more precisely, vector embeddings. Because AI models work with vector embeddings, vector databases are basically the databases for AI applications. Vector databases offer a feature set of vector operations, most notably vector similarity search, that makes it easy and fast to work with vector embeddings and in conjunction with AI models.
When and why do you need a vector database?
Given the significance of vector embeddings (vectors) for AI models, particularly Large Language Models (LLMs) and AI applications, vector databases are now integral to the AI technology stack. They can be used to:
Train AI models (e.g. ML model training, LLM training) Vector databases manage the datasets large models are trained on. Training AI models typically entails finding patterns in large data sets. Training ML models often involves finding patterns in large datasets. Vector databases significantly speed up identifying patterns and finding relationships by enabling efficient retrieval of similar data points.
Speed up AI model / LLM responses Vector databases use various techniques to speed up vector retrieval and similarity search, e.g. compression and filtering. They accelerate both model training and inference, thus, enhancing the performance of generative AI applications. By optimizing vector retrieval and similarity search, vector dbs can enhance the efficiency and scalability of AI applications that rely on high-dimensional data representations
Add long-term memory to AI models and LLMs Vector databases add long term memory to AI applications in two ways: They persist the history to 1. continue on the tasks or conversation later as needed and 2. to personalize and enhance the model for better-fitting results.
Enable Multimodel Search Vector databases serve as the backbone to jointly analyze vectors from multimodal data (text, image, audio, and video) for unified multimodal search and analytics. The use of a combination of vectors from different modalities enables a deeper understanding of the information, leading to more accurate and relevant search results.
Enhancing LLMs responses, primarily “RAG” With a vector database, you have additional knowledge to enhance the quality of a model’s responses and to decrease hallucinations; real-time updates, as well as personalized responses, become possible.
Perform Similarity Search / Semantic Retrieval Vector databases are the heart and soul of semantic retrieval and similarity search. Vector search often works better than „full-text search“ (FTS) as it finds related objects that share the same semantics/meaning instead of matching the exact keyword. Thus, it is possible to handle synonyms, ambiguous language, as well as broad and fuzzy queries.
Cache: Reduce LLM calls Vector databases are used to cache similar queries and responses can be used as a lookup prior to calling the LLM. This saves resources, time, and costs.
The shift to on-device computation (aka Edge Computing)
Edge Computing is in its essence a decentralized computing paradigm and based on Edge Computing, AI on decentralized devices (aka Edge AI) becomes possible. Note: In computing, we have regularly seen shifts from centralized to decentralized computing and back again.
What is Edge Computing?
Our world is decentralized. Data is produced and needed everywhere, on a myriad of distributed devices like smartphones, TVs, robots, machines, and cars – on the so-called “edge” of the network. It would not only be unsustainable, expensive, and super slow to send all this data to the cloud, but it is also literally unfeasible. So, much of this data simply stays on the device it was created on. To harness the value of this data, the distributed “Edge Computing” paradigm is employed.
When and why do you need Edge Computing?
Edge Computing stores and processes data locally on the device it was created on, e.g. on IoT, Mobile, and other edge devices. In practice, Edge Computing often complements a cloud setup. The benefits of extending the cloud with on-device computing are:
Data ownership/privacy Cloud apps are fundamentally non-private and limit the user’s control over their own data. Edge Computing allows data to stay where it is produced, used, and where it belongs (with the user/on the edge devices). It therefore reduces data security risks, and data privacy and ownership concerns.
Bandwidth constraints and the cost of data transmission Ever growing data volumes strain bandwidth and associated network/cloud costs, even with advanced technologies like 5G/6G networks. Storing data locally in a structured way at the edge, such as in an on-device database, is necessary to unlock the power of this data. At the same time, some of this data can still be made available centrally (in the cloud or on an on-premise server), combining the best of both worlds.
Fast response rates and real-time data processing Doing the processing directly on the device is much faster than sending data to the cloud and waiting for a response (latency). With on-device data storage and processing, real-time decision making is possible.
Sustainability By reducing data overhead and unnecessary data transfers, you can cut down 60-90% of data traffic, thereby significantly reducing the CO2 footprint of an application. A welcome side effect is that this also lowers costs tremendously.
Edge AI needs on-device vector databases
Every megashift in computing is empowered by specific infrastructure software, like e.g. databases. Shifting from AI to Edge AI, we still see a notable gap: On-device support for vector data management (the typical AI data) and data synchronization capabilities (to update AI models across devices). To efficiently support Edge AI, vector databases that run locally, on edge devices, are as crucial as they are on servers today. So far, all vector databases are cloud / server databases and cannot run on restricted devices like mobile phones and microcontrollers. But moreover, they often don’t run on more capable devices like standard PCs either, or only with really bad performance. To empower everyday life AI that works anytime all around us, we therefore need a database that can run performantly on a wide variety of devices on the edge of the network.
In fact, vector databases may be even more important on the edge than they are in cloud / server environments. On the edge, the tradeoff between accuracy and performance is a much more delicate line to walk, and vector databases are a way to balance the scales.
On-device AI: Use Cases and why they need an Edge Vector Database
Seamless AI support where it is needed most, on everyday devices and all the things around us needs an optimized local AI tech stack that runs efficiently on the devices. From private home appliences to on-premise devices in business settings, medical equipment in healthcare, digital infrastructure in urban environments, or just mobile phones, you name it: To empower these devices with advanced AI applications, you need local vector databases. From the broad scope of AI’s impact in various fields, let’s focus on some specific examples to make it more tangible: the integration of AI within vehicle onboard systems and the use of Edge AI in healthcare.
Vehicle onboard AI and edge vector databases – examples
Imagine a car crashing because the car software was waiting on the cloud to respond – unthinkable. The car is therefore one of the most obvious use cases for on-device AI.
Any AI application is only as good as its data. A car today is a complex distributed system on wheels, traversing a complex decentralized world. Its complexity is permanently growing due to increased data (7x more data per car generation), devices, and the number of functions. Making use of the available data inside the car and managing the distributed data flows is therefore a challenge in itself. Useful onboard AI applications depend on an on-device vector database (Edge AI). Some in-car AI application examples:
Advanced driver assistance systems (ADAS) ADAS benefit in a lot of areas from in-vehicle AI. Let’s look, for example, at driver behaviour: By monitoring the eye movements and head, ADAS can determine when the driver shows any signs of unconcentrated driving, e.g., drowsiness. Using an on-device database, the ADAS can use the historic data, the realtime data, and other car data, like, e.g., the driving situation, to deduce its action and issue alerts, avoid collisions, or suggest other corrective measures.
Personalized, next-gen driver experience With an on-device database and Edge AI, an onboard AI can analyze driver behavior and preferences over a longer period of time and combine it with other available data to optimize comfort and convenience for a personalised driving experience that goes way beyond a saved profile. For example, an onboard AI can adjust the onboard entertainment system continually to the driver’s detected state, the driving environment, and the personal preferences.
Applications of Edge AI in Healthcare – examples
Edge Computing has seen massive growth in healthcare applications in the last years as it helps to maintain the privacy of patients and provides the reliability and speed needed. Artificial intelligence is also already in wide use making healthcare smarter and more accurate than ever before. With the means for Edge AI at hand, this transformation of the healthcare industry will become even more radical. With Edge AI and on-device vector databases, healthcare can rely on smart devices to react in realtime to users’ health metrics, provide personalized health recommendations, and offer assistance during emergencies – anytime and anyplace, with or without an Internet connection. And while ensuring data security, privacy, and ownership. Some examples:
Personalized health recommendations By monitoring the user’s health data and lifestyle factors (e.g. sleep hours, daily sports activity) combined with their historic medical data, if available, AI apps can help detect early signs of health issues or potential health risks for early diagnosis and intervention. The Ai app can provide personalized recommendations for exercise, diet, or medication adherence. While this case does not rely on real-time analysis and fast feedback as much as the previous example, it benefits from an edge vector database in regards to data privacy and security.
Point of care realtime decision support By deploying AI algorithms on medical devices, healthcare providers can receive immediate recommendations, treatment guidelines, and alerts based on patient-specific data. One example of where this is used with great success, is in surgeries. An operating room, today, is a complex environment with many decentralized medical devices that requires teams to process, coordinate, and act upon several information sources at one time. Ultra-low latency streaming of surgical video into AI-powered data processing workflows on-site, enables surgeons to make better informed decisions, helps them detect abnormalities earlier, and focus on the core of their task.
Edge AI: Clearing the Path for AI anywhere, anytime
For an AI-empowered world when and where needed, we still have to overcome some technical challenges. With AI moving so fast, this seems however quite close. The move into this new era of ubiqutuous AI needs Edge AI infrastructure. Only when Edge AI is so easy to implement and deploy as cloud AI, will we see the ecosystem thriving and bringing AI functionalities that work anytime and anyplace to everyone. An important corner stone will be on-device vector databases as well as new AI frameworks and models, which are specifically designed to address Edge Computing constraints. Some of the corresponding recent advances in the AI area include “LLM in a Flash” (a novel technique from Apple for effective inference of LLMs at the edge) and Liquid Neural Networks (designed for continuous learning and adaptation on edge devices). There’s more to come, follow us to keep your edge on Edge AI News.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.