Easily empower your iOS and macOS apps with fast, private, and sustainable AI features. All you need is a Small Language Model (SLM; aka “small LLM”) and ObjectBox – our on-device vector database built for Swift apps. This gives you a local semantic index for fast on-device AI features like RAG or GenAI that run without an internet connection and keep data private.
The recently demonstrated “Apple Intelligence” features are precisely that: a combination of on-device AI models and a vector database (semantic index). Now, ObjectBox Swift enables you to add the same kind of AI features easily and quickly to your iOS apps right now.
Typical AI apps use data (e.g. user-specific data, or company-specific data) and multiple queries to enhance and personalize the quality of the model’s response and perform complex tasks. And now, for the very first time, with the release of ObjectBox 4.0, this will be possible locally on restricted devices.
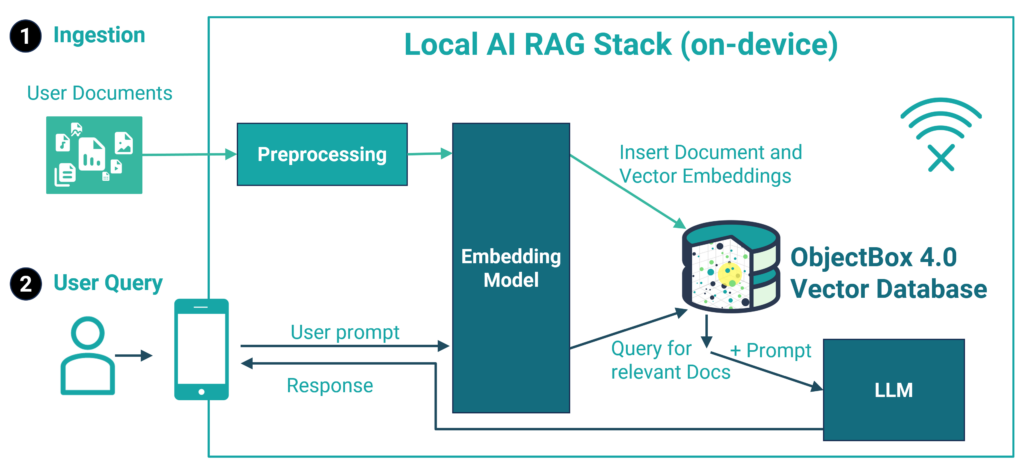
Local AI Tech Stack Example for on-device RAG
Swift on-device Vector Database and search for iOS and MacOS
With the ObjectBox Swift 4.0 release, it is possible to create a scalable vector index on floating point vector properties. It’s a very special index that uses an algorithm called HNSW. It’s scalable because it can find relevant data within millions of entries in a matter of milliseconds. Let’s pick up the cities example from our vector search documentation. Here, we use cities with a location vector and want to find the closest cities (a proximity search). The Swift class for the City entity shows how to define an HNSW index on the location:
1
2
3
4
5
6
7
8
9
10
// objectbox: entity
classCity{
varid:Id=0
varname:String?
// objectbox:hnswIndex: dimensions=2
varlocation:[Float]?
}
</code><!--wp:paragraph--><!--/wp:preformatted-->
Inserting City objects with a float vector and HNSW index works as usual, the indexing happens behind the scenes:
1
2
3
4
5
6
7
let box:Box<city>=store.box()
trybox.put([
City("Barcelona",[41.385063,2.173404]),
City("Nairobi",[-1.292066,36.821945]),
City("Salzburg",[47.809490,13.055010]),
])
</city></code><!--wp:paragraph--><!--/wp:html-->
To then find cities closest to a location, we do a nearest neighbor search using the new query condition and “find with scores” methods. The nearest neighbor condition accepts a query vector, e.g. the coordinates of Madrid, and a count to limit the number of results of the nearest neighbor search, here we want at max 2 cities. The find with score methods are like a regular find, but in addition return a score. This score is the distance of each result to the query vector. In our case, it is the distance of each city to Madrid.
1
2
3
4
5
6
7
8
9
10
11
12
let madrid=[40.416775,-3.703790]// query vector
// Prepare a Query object to search for the 2 closest neighbors:
The ObjectBox on-device vector database empowers AI models to seamlessly interact with user-specific data — like texts and images — directly on the device, without relying on an internet connection. With ObjectBox, data never needs to leave the device, ensuring data privacy.
Thus, it’s the perfect solution for developers looking to create smarter apps that are efficient and reliable in any environment. It enhances everything from personalized banking apps to robust automotive systems.
ObjectBox: Optimized for Resource Efficiency
At ObjectBox, we specialize on efficiency that comes from optimized code. Our hearts beat for creating highly efficient and capable software that outperforms alternatives on small and big hardware. ObjectBox maximizes speed while minimizing resource use, extending battery life, and reducing CO2 emissions.
With this expertise, we took a unique approach to vector search. The result is not only a vector database that runs efficiently on constrained devices but also one that outperforms server-side vector databases (see first benchmark results; on-device benchmarks coming soon). We believe this is a significant achievement, especially considering that ObjectBox still upholds full ACID properties (guaranteeing data integrity).
Cloud/server vector databases vs. On-device/Edge vector databases
Also, keep in mind that ObjectBox is a fully capable database. It allows you to store complex data objects along with vectors. Thus, you have the full feature set of a database at hand. It empowers hybrid search, traceability, and powerful queries.
Use Cases / App ideas
ObjectBox can be used for a million different things, from empowering generative AI features in mobile apps to predictive maintenance on ECUs in cars to AI-enhanced games. For iOS apps, we expect to see the following on-device AI use cases very soon:
Across all categories we’ll see Chat-with-files apps:
Travel: Imagine chatting to your favorite travel guide offline, anytime, anywhere. No need to carry bulky paper books, or scroll through a long PDF on your mobile.
Research: Picture yourself chatting with all the research papers in your field. Easily compare studies and findings, and quickly locate original quotes.
Travel: Imagine chatting to your favorite travel guide offline, anytime, anywhere. No need to carry bulky paper books, or scroll through a long PDF on your mobile
Research: Picture yourself chatting with all the research papers in your field. Easily compare studies and findings, and quickly locate original quotes.
Education: Educational apps featuring “chat-with-your-files” functionality for learning materials and research papers. But going beyond that, they generate quizzes and practice questions to help people solidify knowledge.
Lifestyle – from Coaching to Health
Health: Apps offering personalized recommendations based on scientific research, your preferences, habits, and individual health data. This includes data tracked from your device, lab results, and doctoral diagnosis.
Productivity: Personal assistants for all areas of life
Family Management: Interact with assistants tailored to specific roles. Imagine a parent’s assistant that monitors school channels, chat groups, emails, and calendars. Its goal is to automatically add events like school plays, remind you about forgotten gym bags, and even suggest birthday gifts for your child’s friends.
Professional Assistants: Imagine being a busy sales rep on the go, juggling appointments and travel. A powerful on-device sales assistant can do more than just automation. It can prepare contextual and personalized follow-ups instantly. For example, by summarizing talking points, attaching relevant company documents, and even suggesting who to CC in your emails.
Run the local AI Stack with a Language Model (SLM, LLM)
Recent Small Language Models (SMLs) already demonstrate impressive capabilities while being small enough to run on e.g. mobile phones. To run the model on-device of an iPhone or a macOS computer, you need a model runtime. On Apple Silicone the best choice in terms of performance typically MLX – a framework brought to you by Apple machine learning research. It supports the hardware very efficiently by supporting CPU/GPU and unified memory.
To summarize, you need these three components to run on-device AI with an semantic index:
ObjectBox: vector database for the semantic index
Models: choose an embedding model and a language model to match your requirements
ObjectBox 4.0 is the very first on-device, local vector database for Android and Java developers to enhance their apps with local AI capabilities (Edge AI). A vector database facilitates advanced vector data processing and analysis, such as measuring semantic similarities across different document types like images, audio files, and texts. A classic use case would be to enhance a Large Language Model (LLM), or a Small Language Model (SLM, like e.g. the Phi-3), with your domain expertise, your proprietary knowledge, and / or your private data. Combining the power of AI models with a specific knowledge base empowers high-quality, perfectly matching results a generic model simply cannot provide. This is called “retrieval-augmented generation” (RAG). Because ObjectBox works on-device, you can now do on-device RAG with data that never leaves the device and therefore stays 100% private. This is your chance to explore this technology on-device.
Vector Search (Similarity Search)
With this release, it is possible to create a scalable vector index on floating point vector properties. It’s a very special index that uses an algorithm called HNSW (Hierarchical Navigable Small World). It’s scalable because it can find relevant data within millions of entries in a matter of milliseconds.
We pick up the example used in our vector search documentation. In short, we use cities with a location vector to perform proximity search. Here is the City entity and how to define a HNSW index on the location:
To perform a nearest neighbor search, use the new nearestNeighbors(queryVector, maxResultCount) query condition and the new “find with scores” query methods (the score is the distance to the query vector). For example, let’s find the 2 closest cities to Madrid:
In the cities example above, the vectors were straight forward: they represent latitude and longitude. Maybe you already have vector data as part of your data. But often, you don’t. So where do you get the vector emebeddings of texts, images, video, audio files from?
For most AI applications, vectors are created by a embedding model. There are plenty of embedding models to choose from, but first you have to decide if it should run in the cloud or locally. Online embeddings are the easier way to get started and great for first testing; you can set up an account at your favorite AI provider and create embeddings online (only).
Depending on how much you care about privacy, you can also run embedding models locally and create your embeddings on your own device. There are a couple of choices for desktop / server hardware, e.g. check these on-device embedding models. For Android, MediaPipe is a good start as it has embedders for text and images.
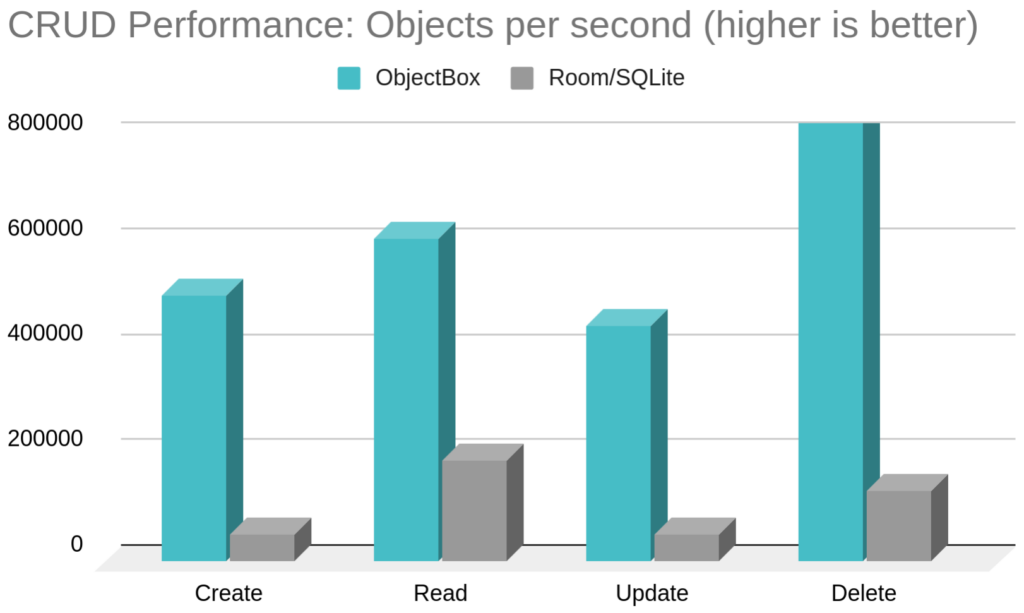
Updated open source benchmarks 2024 (CRUD)
A new release is also a good occasion to update our open source benchmarks. The Android performance benchmark app provides many more options, but here are the key results:
CRUD is short for the basic operations a database does: create, read, update and delete. It’s an important metric for the general efficiency of a database.
Disclaimer 1: our focus is the “Object” performance (you may find a hint for that in our product name 🙂); so e.g. relational systems may perform a bit better when you directly work with raw columns and rows.
Disclaimer 2: ObjectBox delete performance was cut off at 800k per second to keep the Y axis within reasonable bounds. The actually measured value was 2.5M deletes per second.
Disclaimer 3: there cannot be enough disclaimers on any performance benchmark. It’s a complex topic where details matter. It’s best if you make your own picture for your own use case. We try to give a fair “arena” with our open source benchmarks, so it could be a starting point for you.
Feedback and Outlook: On-device vector search Benchmarks for Android coming soon
We’re still working on a lot of stuff (as always ;)) and with on-device / local vector search being a completely new technology for Android, we need your feedback, creativity and support more than ever. We’ll also soon release benchmarks on the vector search. Follow us on LinkedIn, GitHub, or Twitter to keep up-to-date.
Python developers can now use the very first on-device vector database for AI apps that run everywhere, on Mobile, IoT, desktops, other commodity hardware, any cloud, bare metal, you name it. The ObjectBox embedded database conveniently stores and manages Python objects and vectors, offering highly performant vector search alongside CRUD operations for objects on any device. Get started with this video tutorial by Krish Naik, or this one.
What is ObjectBox?
ObjectBox is a lightweight embedded database for objects and vectors. Note that “objects” here refers to programming language objects, e.g. instances of a Python class. And because it was built for this purpose, ObjectBox is typically the fastest database option in this category. In terms of performance, it easily beats wrappers and ORMs running on top of SQL databases. This is because middle layers like SQL and row/column mapping simply do not exist.
ObjectBox is also an on-device vector database storing high dimensional vector data and offering a highly scalable vector search algorithm (HNSW). Even with millions of documents, ObjectBox is capable of finding nearest neighbors within milliseconds on commodity hardware. And for ObjectBox, a vector is “just another” property type and thus, you can combine vector data with regular data using your own data model.
Having an easy-to-use API is a top priority for ObjectBox. The following example uses a City entity, which has a name and a location. The latter is a two dimensional vector of latitude and longitude. We create a Store (aka the database) with default options, and use a Box to insert a list of Cities:
With cities stored in the database, let’s do a simple search for cities starting with “Be”:
Vector search follows the same pattern. This query locates the nearest neighbors to a given location:
LangChain Integration
ObjectBox is integrated as a Vector Database in LangChain via the langchain-objectbox package:
pip install langchain-objectbox --upgrade
Then, create an ObjectBox VectorStore using e.g. one of the from_ class methods e.g. from_texts class method:
from langchain_objectbox.vectorstores import ObjectBox obx_vectorstore = ObjectBox.from_texts(texts, embeddings, ...)
We will look into details in one of our next blog posts.
Vector Search Performance
While ObjectBox is a small database, you can expect great performance. We ran a quick benchmark on using the popular and independent ANN benchmark open source suite. First results indicate that ObjectBox’ vector search is quite fast and that it can even compete with vector databases built for servers and the cloud. For more details, we will have a special ANN benchmark post that goes in more detail soon (follow us to stay up-to-date: LinkedIn, Twitter).
From Zero to 4: our first stable Python Release
We jumped directly to version 4.0 to align with our “core” version. The core of ObjectBox is written in high-performance C++ and with the release of vector search, we updated its version to 4.0. Thus you already get all the robustness you would expect from a 4.0 version of a product that has been battle tested for years. By aligning the major version, it’s also easy to tell that all ObjectBox bindings with version 4 include vector search.
What’s next?
There are a lot of features still in the queue. For example our Python binding does not support relations yet. Also we would like to do further benchmarks and performance work specific to Python. We are also open for contributions, check our GitHub repository.
The new on-device vector database enables advanced AI applications on small restricted devices like mobile phones, Raspberry Pis, medical equipment, IoT gadgets and all the smart things around you. It is the missing piece to a fully local AI stack and the key technology to enable AI language models to interact with user specific data like text and images without an Internet connection and cloud services.
An AI Technology Enabler
Recent AI language models (LLMs) demonstrated impressive capabilities while being small enough to run on e.g. mobile phones. Recent examples include Gemma, Phi3 and OpenELM. The next logical step from here is to use these LLMs for advanced AI applications that go beyond a mere chat. A new generation of apps is currently evolving. These apps create “flows” with user specific data and multiple queries to the LLM to perform complex tasks. This is also known as RAG (retrieval augmented generation), which, in its simplest form, allows one to chat with your documents. And now, for the very first time, this will be possible to do locally on restricted devices using a fully fledged embedded database.
What is special about ObjectBox Vector Search?
We know restricted devices. Where others see limitations, we see the potential and we have repeatedly demonstrated creating superefficient software for these. And thus maximizing speed, minimizing resource use, saving battery life and CO2. With this knowledge, we approached vector search in a unique way.
Efficient memory management is the key. The challenge with vector data is that on the one hand, it consumes a lot of memory – while on the other hand, relevant vectors must be present in memory to compute distances between vectors efficiently. For this, we introduced a special multi-layered caching that gives the best performance for the full range of devices; from memory-constrained small devices to large machines that can keep millions of vectors in memory. This worked out so well that we saw ObjectBox outperform several vector databases built for servers (open source benchmarks coming soon). This is no small feat given that ObjectBox still holds up full ACID properties, e.g. caching must be transaction-aware.
Also, keep in mind that ObjectBox is a fully capable database that allows you to store complex data objects along with vectors. From an ObjectBox data model point of view, a vector is “just” another property type. This allows you to store all your data (vectors along with objects) in a single database. This “one database” approach also includes queries. You can already combine vector search with other conditions. Note that some limitations still apply with this initial release. Full hybrid search is close to being finished and will be part of one of the next releases.
In short, the following features make ObjectBox a unique vector database:
Embedded Database that runs inside your application without latency
Vector search based is state-of-the-art HNSW algorithm that scales very well with growing data volume
HNSW is tightly integrated within our internal database. Vector Search doesn’t just run “on top of database persistence”.
With this deep integration we do not need to keep all vectors in memory.
Multi-layered caching: if a vector is not in-memory, ObjectBox fetches it from disk.
Not just a vector database: you can store any data in ObjectBox, not just vectors. You won’t need a second database.
Low minimum hardware requirements: e.g. an old Raspberry Pi comfortably runs ObjectBox smoothly.
Low memory footprint: ObjectBox itself just takes a few MB of memory. The entire binary is only about 3 MB (compressed around 1 MB).
Scales with hardware: efficient resource usage is also an advantage when running on more capable devices like the latest phones, desktops and servers.
ObjectBox additionally offers commercial editions, e.g. a Server Cluster mode, GraphQL, and of course, ObjectBox Sync, our data synchronization solution.
Why is this relevant? AI anywhere & anyplace
With history repeating itself, we think AI is in a “mainframe era” today. Just like clunky computers from decades before, AI is restricted to big and very expensive machines running far away from the user. In the future, AI will become decentralized, shifting to the user and their local devices. To support this shift, we created the ObjectBox vector database. Our vision is a future where AI can assist everyone, anytime, and anywhere, with efficiency, privacy, and sustainability at its core.
What do we launch today?
Today, we are releasing ObjectBox 4.0 with Vector Search for a variety of languages:
*) We acknowledge Python’s popularity within the AI community and thus have invested significantly in our Python binding over the last months to make it part of this initial release. Since we still want to smooth out some rough edges with Python, we decided to label Python an alpha release. Expect Python to quickly catch up and match the comfort of our more established language bindings soon (e.g. automatic ID and model handling).
One more thing: ObjectBox Open Source Database (OSS)
We are also very happy to announce that we will fully open source the core of ObjectBox. As a company we follow the open core model. Since we still have some cleaning up to do, this will happen in one of the next releases, likely 4.1.
“Release week”
With today’s initial releases, we are far from done yet. Starting next Tuesday, you can expect additional announcements from us. Follow us to get the news as soon as it is released.
What’s next?
This is our very first version of a “vector database”. And while we are very happy with this release, there are still so many things to do! For example, we will optimize vector search by adding vector quantization and integrate it more tightly with our data synchronization. We are also focusing on expanding our solution’s reach through strategic partnerships. If you think you are a good fit, let us know. And as always, we are very eager to get some feedback from you! Take care.
AI anywhere and anytime - free from Internet dependencies & 100% private
Edge AI is an often overlooked aspect of AI’s natural evolution. It is basically the move of AI functionalities away from the cloud (or powerful server infrastructure) towards decentralized (typically less powerful) devices at the network’s edges, including on mobile phones, smartwatches, IoT devices, microcontrollers, ECUs, or simply your local computer. Or in more broadly speaking: “Edge AI” means AI that works directly on-device, “local AI“.
Therefore, Edge AI apps work independently from an internet connection, offline as well as online. So, they are ideal for low, intermittent, or no connectivity scenarios. They are reliably available, more sustainable, and – of course – way faster on-device than anything hosted in the cloud. On-device AI apps can empower realtime AI anytime and anyplace.
The importance of vector databases for AI applications
To enable powerful on-device AI applications, the on-device (edge) technology stack needs local vector databases. So, before diving deeper into Edge AI, we’ll dive into vector databases first. Jump this section, if you are already familiar with them.
What is a vector database?
Just as SQL databases handle data in rows and columns, graph databases manage graphs, object databases store objects, vector databases store and manage large data sets of vectors, or more precisely, vector embeddings. Because AI models work with vector embeddings, vector databases are basically the databases for AI applications. Vector databases offer a feature set of vector operations, most notably vector similarity search, that makes it easy and fast to work with vector embeddings and in conjunction with AI models.
When and why do you need a vector database?
Given the significance of vector embeddings (vectors) for AI models, particularly Large Language Models (LLMs) and AI applications, vector databases are now integral to the AI technology stack. They can be used to:
Train AI models (e.g. ML model training, LLM training) Vector databases manage the datasets large models are trained on. Training AI models typically entails finding patterns in large data sets. Training ML models often involves finding patterns in large datasets. Vector databases significantly speed up identifying patterns and finding relationships by enabling efficient retrieval of similar data points.
Speed up AI model / LLM responses Vector databases use various techniques to speed up vector retrieval and similarity search, e.g. compression and filtering. They accelerate both model training and inference, thus, enhancing the performance of generative AI applications. By optimizing vector retrieval and similarity search, vector dbs can enhance the efficiency and scalability of AI applications that rely on high-dimensional data representations
Add long-term memory to AI models and LLMs Vector databases add long term memory to AI applications in two ways: They persist the history to 1. continue on the tasks or conversation later as needed and 2. to personalize and enhance the model for better-fitting results.
Enable Multimodel Search Vector databases serve as the backbone to jointly analyze vectors from multimodal data (text, image, audio, and video) for unified multimodal search and analytics. The use of a combination of vectors from different modalities enables a deeper understanding of the information, leading to more accurate and relevant search results.
Enhancing LLMs responses, primarily “RAG” With a vector database, you have additional knowledge to enhance the quality of a model’s responses and to decrease hallucinations; real-time updates, as well as personalized responses, become possible.
Perform Similarity Search / Semantic Retrieval Vector databases are the heart and soul of semantic retrieval and similarity search. Vector search often works better than „full-text search“ (FTS) as it finds related objects that share the same semantics/meaning instead of matching the exact keyword. Thus, it is possible to handle synonyms, ambiguous language, as well as broad and fuzzy queries.
Cache: Reduce LLM calls Vector databases are used to cache similar queries and responses can be used as a lookup prior to calling the LLM. This saves resources, time, and costs.
The shift to on-device computation (aka Edge Computing)
Edge Computing is in its essence a decentralized computing paradigm and based on Edge Computing, AI on decentralized devices (aka Edge AI) becomes possible. Note: In computing, we have regularly seen shifts from centralized to decentralized computing and back again.
What is Edge Computing?
Our world is decentralized. Data is produced and needed everywhere, on a myriad of distributed devices like smartphones, TVs, robots, machines, and cars – on the so-called “edge” of the network. It would not only be unsustainable, expensive, and super slow to send all this data to the cloud, but it is also literally unfeasible. So, much of this data simply stays on the device it was created on. To harness the value of this data, the distributed “Edge Computing” paradigm is employed.
When and why do you need Edge Computing?
Edge Computing stores and processes data locally on the device it was created on, e.g. on IoT, Mobile, and other edge devices. In practice, Edge Computing often complements a cloud setup. The benefits of extending the cloud with on-device computing are:
Data ownership/privacy Cloud apps are fundamentally non-private and limit the user’s control over their own data. Edge Computing allows data to stay where it is produced, used, and where it belongs (with the user/on the edge devices). It therefore reduces data security risks, and data privacy and ownership concerns.
Bandwidth constraints and the cost of data transmission Ever growing data volumes strain bandwidth and associated network/cloud costs, even with advanced technologies like 5G/6G networks. Storing data locally in a structured way at the edge, such as in an on-device database, is necessary to unlock the power of this data. At the same time, some of this data can still be made available centrally (in the cloud or on an on-premise server), combining the best of both worlds.
Fast response rates and real-time data processing Doing the processing directly on the device is much faster than sending data to the cloud and waiting for a response (latency). With on-device data storage and processing, real-time decision making is possible.
Sustainability By reducing data overhead and unnecessary data transfers, you can cut down 60-90% of data traffic, thereby significantly reducing the CO2 footprint of an application. A welcome side effect is that this also lowers costs tremendously.
Edge AI needs on-device vector databases
Every megashift in computing is empowered by specific infrastructure software, like e.g. databases. Shifting from AI to Edge AI, we still see a notable gap: On-device support for vector data management (the typical AI data) and data synchronization capabilities (to update AI models across devices). To efficiently support Edge AI, vector databases that run locally, on edge devices, are as crucial as they are on servers today. So far, all vector databases are cloud / server databases and cannot run on restricted devices like mobile phones and microcontrollers. But moreover, they often don’t run on more capable devices like standard PCs either, or only with really bad performance. To empower everyday life AI that works anytime all around us, we therefore need a database that can run performantly on a wide variety of devices on the edge of the network.
In fact, vector databases may be even more important on the edge than they are in cloud / server environments. On the edge, the tradeoff between accuracy and performance is a much more delicate line to walk, and vector databases are a way to balance the scales.
On-device AI: Use Cases and why they need an Edge Vector Database
Seamless AI support where it is needed most, on everyday devices and all the things around us needs an optimized local AI tech stack that runs efficiently on the devices. From private home appliences to on-premise devices in business settings, medical equipment in healthcare, digital infrastructure in urban environments, or just mobile phones, you name it: To empower these devices with advanced AI applications, you need local vector databases. From the broad scope of AI’s impact in various fields, let’s focus on some specific examples to make it more tangible: the integration of AI within vehicle onboard systems and the use of Edge AI in healthcare.
Vehicle onboard AI and edge vector databases – examples
Imagine a car crashing because the car software was waiting on the cloud to respond – unthinkable. The car is therefore one of the most obvious use cases for on-device AI.
Any AI application is only as good as its data. A car today is a complex distributed system on wheels, traversing a complex decentralized world. Its complexity is permanently growing due to increased data (7x more data per car generation), devices, and the number of functions. Making use of the available data inside the car and managing the distributed data flows is therefore a challenge in itself. Useful onboard AI applications depend on an on-device vector database (Edge AI). Some in-car AI application examples:
Advanced driver assistance systems (ADAS) ADAS benefit in a lot of areas from in-vehicle AI. Let’s look, for example, at driver behaviour: By monitoring the eye movements and head, ADAS can determine when the driver shows any signs of unconcentrated driving, e.g., drowsiness. Using an on-device database, the ADAS can use the historic data, the realtime data, and other car data, like, e.g., the driving situation, to deduce its action and issue alerts, avoid collisions, or suggest other corrective measures.
Personalized, next-gen driver experience With an on-device database and Edge AI, an onboard AI can analyze driver behavior and preferences over a longer period of time and combine it with other available data to optimize comfort and convenience for a personalised driving experience that goes way beyond a saved profile. For example, an onboard AI can adjust the onboard entertainment system continually to the driver’s detected state, the driving environment, and the personal preferences.
Applications of Edge AI in Healthcare – examples
Edge Computing has seen massive growth in healthcare applications in the last years as it helps to maintain the privacy of patients and provides the reliability and speed needed. Artificial intelligence is also already in wide use making healthcare smarter and more accurate than ever before. With the means for Edge AI at hand, this transformation of the healthcare industry will become even more radical. With Edge AI and on-device vector databases, healthcare can rely on smart devices to react in realtime to users’ health metrics, provide personalized health recommendations, and offer assistance during emergencies – anytime and anyplace, with or without an Internet connection. And while ensuring data security, privacy, and ownership. Some examples:
Personalized health recommendations By monitoring the user’s health data and lifestyle factors (e.g. sleep hours, daily sports activity) combined with their historic medical data, if available, AI apps can help detect early signs of health issues or potential health risks for early diagnosis and intervention. The Ai app can provide personalized recommendations for exercise, diet, or medication adherence. While this case does not rely on real-time analysis and fast feedback as much as the previous example, it benefits from an edge vector database in regards to data privacy and security.
Point of care realtime decision support By deploying AI algorithms on medical devices, healthcare providers can receive immediate recommendations, treatment guidelines, and alerts based on patient-specific data. One example of where this is used with great success, is in surgeries. An operating room, today, is a complex environment with many decentralized medical devices that requires teams to process, coordinate, and act upon several information sources at one time. Ultra-low latency streaming of surgical video into AI-powered data processing workflows on-site, enables surgeons to make better informed decisions, helps them detect abnormalities earlier, and focus on the core of their task.
Edge AI: Clearing the Path for AI anywhere, anytime
For an AI-empowered world when and where needed, we still have to overcome some technical challenges. With AI moving so fast, this seems however quite close. The move into this new era of ubiqutuous AI needs Edge AI infrastructure. Only when Edge AI is so easy to implement and deploy as cloud AI, will we see the ecosystem thriving and bringing AI functionalities that work anytime and anyplace to everyone. An important corner stone will be on-device vector databases as well as new AI frameworks and models, which are specifically designed to address Edge Computing constraints. Some of the corresponding recent advances in the AI area include “LLM in a Flash” (a novel technique from Apple for effective inference of LLMs at the edge) and Liquid Neural Networks (designed for continuous learning and adaptation on edge devices). There’s more to come, follow us to keep your edge on Edge AI News.
We use cookies to ensure that we give you the best experience on our website. If you continue to use this site we will assume that you are happy with it.Ok

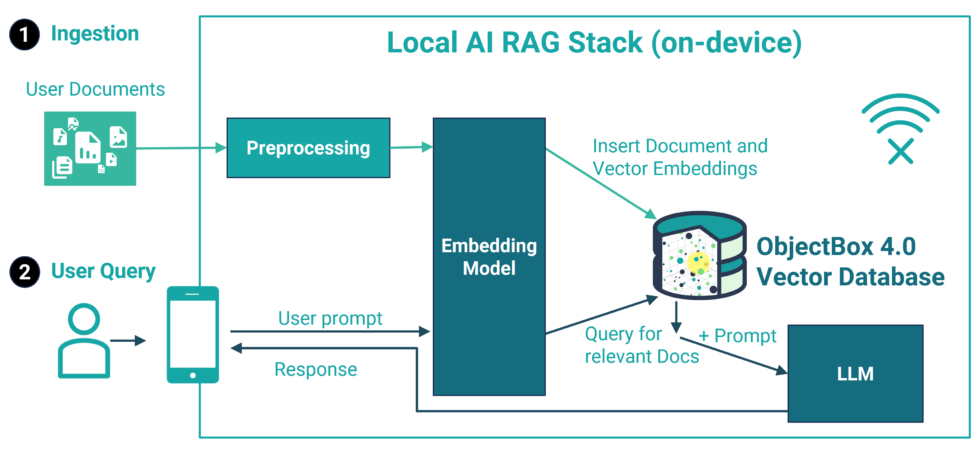 Local AI Tech Stack Example for on-device RAG
Local AI Tech Stack Example for on-device RAG
 Cloud/server vector databases vs. On-device/Edge vector databases
Cloud/server vector databases vs. On-device/Edge vector databases